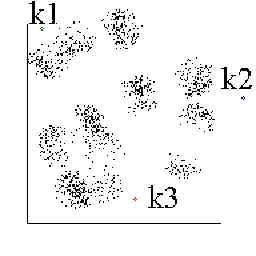
Figura 1:
Foram definidas 3 médias k1 (verde), k2 (azul),
k3 (vermelha) que serão usadas para classificar os pontos do conjunto
especificado na figura.
Resumo do Capítulo
Neste relatório estão descritos os trabalhos
que se realizaram no período final da concessão da bolsa
de Iniciação Científica, caracterizados pelo estudo
de artigos relacionados a detecção de características
faciais em imagens, além da implementação de cinco
algoritmos que conseguem identificar regiões importantes de faces
(olhos, nariz e boca). Comenta-se também problemas apresentados
pelos algoritmos, detalhes de implementação e prováveis
soluções que podem ser tomadas. Para finalizar, comentamos
as melhorias que poderão ser feitas para o problema de detecção
de características faciais nos algoritmos implementados.
1. INTRODUÇÃO
O objetivo deste capíyulo é mostrar como progrediu o projeto de estudos de métodos de visão computacional para reconhecimento de pessoas, feito pelo bolsista Fábio Pará D' Incecco e orientado pelo Prof. Dr. Roberto Marcondes Cesar Junior no segundo período de concessão da bolsa.
Relembramos que o projeto consiste em estudar algoritmos necessários para o reconhecimento de pessoas através de técnicas de visão computacional. Além disso, foram implementados alguns destes em MatLab. A pedido dos revisores do relatório número 1, foram feitos testes estatísticos com um dos algoritmos implementados, que consiste em se comparar o que um ser humano considera como características faciais com o que é detectado pelo algoritmo. Maiores detalhes podem ser vistos na seção 3.
A 2ª fase do projeto foi marcada pela implementação de cinco algoritmos para detecção de características faciais baseados em duas técnicas diferentes, que serão explicadas nas próximas seções. Os algoritmos foram implementados em MatLab, tendo havido também o estudo de artigos sobre o reconhecimento de faces.
Os algoritmos se caracterizam pelo uso de uma técnica de detecção das características faciais que inicialmente realiza detecção das bordas da imagem. Esse processo é usado para reduzir sensivelmente o número de pontos que deverão ser analisados na procura pelas características faciais.
Em seguida, realiza-se um processo de análise de agrupamentos, que será melhor explicado na seção 2. Resumidamente, este consiste em analisar um conjunto de pontos e tentar unir em vários subconjuntos as características que estamos procurando.
A abordagem que adotamos parte do princípio que
em uma face a maior concentração de bordas estão ao
redor dos olhos, narinas e da boca. Assim, é desejável agrupar
esses pontos nas características faciais que procuramos identificar
(olhos, nariz e boca), o que é realizado pelo processo de análise
de agrupamentos mencionado acima.
Na seção 2 será explicada a técnica que foi utilizada para o desenvolvimento e aperfeiçoamento dos algoritmos implementados, iniciando pela definição de conceitos importantes que foram usados nas implementações.
Também será desenvolvido um apanhado geral
dos problemas que ocorreram com essa técnica adotada. Uma discussão
mais aprofundada é encontrada na seção 4.
1.1 BIBLIOGRAFIA DA 2ª FASE DO PROJETO
O objetivo dessa seção é descrever e comentar os artigos científicos [15] e [17] estudados durante a segunda fase do projeto de Iniciação Científica, pois trazem abordagens interessantes para o problema de detecção de características faciais. É importante enfatizar que em relação aos métodos de análise de agrupamentos, foram consultadas as referências [5, 8, 9, 14]
O artigo propõe uma abordagem ao problema de detecção de faces e sua localização em uma imagem usando uma técnica de Teoria dos Grafos, denominada casamento de grafos. Para tanto, usa-se um rigoroso modelo probabilístico para determinar parâmetros otimizados que conduzam a um bom casamento entre os grafos analisados.
É necessário antes de se descrever o algoritmo, explicar o que vem a ser casamento de grafos. O processo consiste em tentar achar uma equivalência entre dois grafos através dos seus vértices e arcos (maiores detalhes podem ser vistos em http://www.icbl.hw.ac.uk/marble/vision/high/matching/graph.htm )
O principal ponto a ser comentado é que o algoritmo tenta localizar, na imagem, um conjunto de características faciais como olhos, nariz e narinas. O algoritmo tenta encontrar essas características independente da localização da face, utilizando para isso transformações geométricas de rotação aplicadas na imagem. Ou seja, a face pode estar deslocada da parte central da imagem, ou pode estar inclinado, etc.
Após essa fase, o próximo passo é transformar as características faciais em vértices de um grafo, enquanto as distâncias entre cada característica são representadas como sendo os arcos do grafo gerado. Um ponto interessante dessa abordagem é que, após uma fase de treinamento do algoritmo, dados os olhos em alguma posição da imagem, sabe-se, aproximadamente, os lugares prováveis onde se encontram nariz e boca, pois somente é necessário completar o subgrafo gerado. O modelo probabilístico é que indica essa possível localização da face na imagem.
Trataremos agora sobre o artigo [17], que traz uma nova abordagem sobre a extração de componentes da face, ou características faciais. A maioria das técnicas de análise de face falham porque tentam usar características geométricas e suas relações para construção de modelos matemáticos. Além disso, outra técnica muito utilizada é recorrer a operações de segmentação da imagem diretamente em nível de cinza. Mas essas técnicas enfrentam problemas de sensibilidade a ruído da imagem, efeitos de iluminação e complexidade da cena analisada, entre outros.
Os autores em [17] propõem uma técnica baseada na localização dos olhos, sobrancelhas, narinas e boca através de transformações geométricas e operações de Processamento de Imagens realizadas diretamente na imagem em nível de cinza. A combinação das quatro componentes faciais gera uma descrição estrutural da face.
É descrito um sistema que foi criado para analisar a face e detectar o seu eixo de simetria. Além disso, todo o trabalho de se encontrar as componentes faciais é realizado através de operadores de simetria, que podem ser especializados para fazer uma análise global da imagem, ou apenas em uma região desta. É importante mencionar que, para agrupar os pontos das componentes faciais, utiliza-se distância Euclidiana e algoritmos de análise de agrupamentos, de maneira análoga à abordagem explorada neste relatório.
Neste artigo as imagens são mais restritivas, pois
trabalha-se com faces horizontais e frontais. Na base de imagens utilizada,
encontram-se faces risonhas, normais, nervosas, em estado de surpresa,
entre outros tipos.
2. ALGORITMOS IMPLEMENTADOS E METODOLOGIA
Iniciaremos a seção definindo conceitos
que serão importantes para o entendimento dos algoritmos desenvolvidos.
2.1 Análise de agrupamentos
É importante antes de iniciarmos a discussão sobre o que fazem os algoritmos, explicarmos os conceitos que foram usados para abordarmos o problema de detecção de características faciais.
CLUSTERING (análise de agrupamentos): É uma técnica de classificação não-supervisionada que se baseia na similaridade entre os objetos (no nosso caso pontos) a serem classificados, usando-se determinadas medidas sobre suas características. Além disso, normalmente o conjunto de treinamento não é rotulado a priori. [6] Muitas vezes, utiliza-se como medida de similaridade a distância de cada ponto a um outro inicial definido como média. Em um mesmo conjunto de pontos podemos ter muitas médias colocadas aleatoriamente, ou de acordo com certo critério, caso se queira um resultado mais apurado.
A principal idéia desse processo é conseguir,
no final, determinar grupos de pontos que se assemelham mais a uma determinada
média. Na figura 1 abaixo, temos um conjunto de pontos antes de
se iniciar o processo.
Figura 1:
Foram definidas 3 médias k1 (verde), k2 (azul),
k3 (vermelha) que serão usadas para classificar os pontos do conjunto
especificado na figura.
Na figura 2 temos o resultado final após a classificação
dos pontos segundo o critério de distância. Ou seja, cada
ponto é colocado no mesmo conjunto da média mais próxima.
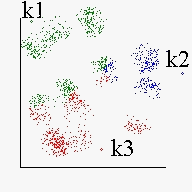
Figura 2:
Os pontos são classificados de acordo com a
média mais próxima. Nesse processo, as médias NÃO
mudaram, mas dependendo do algoritmo utilizado, os seus valores podem ser
alterados.
É importante mencionar que, dada uma coleção de pontos qualquer, ao final do processo, todos os pontos estarão classificados de acordo com alguma média. Assim, pensando em termos de número de elementos do conjunto, no início e no final teremos o mesmo valor.
CLUSTER (Agrupamento): Após o processo de análise de agrupamentos, todos os pontos foram possivelmente classificados de acordo com alguma das médias. Cada conjunto de pontos que foram classificados como mais próximos a uma determinada média chama-se de "cluster" ou agrupamento. Assim, na figura 2 podemos identificar três agrupamentos: um de cor azul pertencente à média k2, outro vermelho correspondente à k3 e outro verde referente à k1. Abaixo são apresentadas algumas das principais abordagens para a técnica de análise de agrupamentos.
ALGORITMO DAS K-MÉDIAS: É um algoritmo de
análise de agrupamentos que parte do princípio que temos
sempre k médias no conjunto de pontos a serem classificados e, conforme
o processo avança, para cada ponto P a ser classificado,
calcula-se uma medida de distância deste até cada uma das
k médias. Com a menor medida calculada, classifica-se o ponto como
pertencente àquele agrupamento ki . Uma nova ki
média é calculada considerando a médias das coordenadas
da ki média original somada com o ponto P
que foi classificado. Ou seja, no R2 com coordenadas
x
e y, considerando que cada ponto ou média tem suas coordenadas
identificadas como uma par (coordenada x, coordenada
y),
temos que:
Um ponto P é da forma : P = (Px ,Py)
E uma média k é da forma: k = (kx , ky)
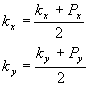
Note que uma (e apenas uma) média pode ser alterada a cada ponto que é classificado.
ALGORITMO DE FORGY: É muito semelhante ao k-médias em termos da definição. A principal mudança é que a média de cada agrupamento só muda após uma primeira classificação de todos os pontos do conjunto de teste [14].
Abaixo, detalha-se melhor o algoritmo de Forgy:
Algoritmo de Forgy
1. Inicialize as k médias dos agrupamentos com k pontos escolhidos como sementes.2. Para cada ponto a ser classificado, encontre (através da medida de distância) a média mais próxima e coloque-o no agrupamento correspondente àquela média.
3. Se nenhum ponto for classificado no passo anterior, pare o processo de classificação.
4. Recompute todas as k médias dos agrupamentos obtidos e retorne a passo 2.
2.2 Detecção de bordas:
Bordas são regiões na imagem que possuem um grande nível de contraste, sua existência em uma imagem representa contornos de objetos. A detecção de bordas é muito usada em segmentação de imagens [9 e 11], onde o objetivo é dividir a imagem em áreas correspondentes a objetos distintos. Representar a imagem através das suas bordas é vantajoso pois reduz sensivelmente a quantidade de dados que estavam sendo guardados na imagem e, ainda assim, sem perder muita informação.
Há várias técnicas usando filtragem
que podem ser usadas para detecção de bordas [veja 4, 5 e
9]. No nosso caso, escolhemos a de convolução de uma matriz
geralmente pequena (3 linhas por 3 colunas) com a imagem em tons de cinza.
O resultado final obtido é uma nova imagem de mesmo tamanho que
a original caracterizada apenas pela existência de zeros ou uns.
Ou seja, a imagem final obtida é binária. Em todas as implementações
decidimos usar o detector de bordas horizontais de Sobel, pois esse se
mostrou mais eficiente em detectar regiões dos olhos, nariz e boca.
Veja maiores detalhes sobre detectores de bordas no relatório 1.
2.3 Descrição do método
O método que adotamos baseia-se na análise de agrupamentos das regiões que serão importantes para nosso estudo de reconhecimento de faces, ou seja, olhos, nariz e boca. Para isso, adaptamos o processo de análise de agrupamentos para que os pontos só sejam classificados caso a sua distância a um agrupamento não ultrapasse um valor de erro. Ou seja, consideramos uma taxa de erro máximo que dado um ponto qualquer, ao se calcular a distância deste à média do agrupamento, o ponto só é classificado caso o valor da distância seja menor que essa taxa.
Com isso, no nosso método, há a possibilidade de um ponto não ser classificado como pertencente a algum agrupamento. Vale lembrar que na definição habitual de análise de agrupamentos, sempre os pontos são rotulados como pertinentes a algum conjunto de uma k média.
Adotamos essa política quanto à classificação dos pontos com a intenção de reduzir o tempo computacional gasto e também para que o resultado apurado fosse mais próximo do que queremos trabalhar, ou seja, regiões próximas dos olhos, nariz e boca. Nosso intuito é exatamente tentar capturar essas características da face usando, para isso, médias bem colocadas nessas regiões da face.
Para aplicarmos o processo de análise de agrupamentos à imagem original, fazemos um processo de detecção de bordas que vem a reduzir drasticamente o número de pontos a serem tratados, pois apenas os contornos mais fortes restam. Lembrando que o processo de detecção de bordas retorna uma imagem binária, o próximo passo que temos a fazer é juntar todos os pontos em um só conjunto e trabalhar com este para encontrar os agrupamentos que desejamos encontrar. O processo de reunir os pontos em um só conjunto não vem a ser muito custoso, pois, no MatLab, isso é implementado como função primitiva.
Antes de iniciarmos a descrição do processo de análise de agrupamentos, definimos as médias que utilizaremos para separar as nossas regiões de interesse, que são olhodir, para o olho direito, olhoesq, para olho esquerdo, nariz para a área do nariz, mais especificamente as narinas e boca para a região da boca. Para determinar o valor das coordenadas x e y de cada média, retiramos uma amostragem com um conjunto de faces da nossa base de imagens e definimos visualmente onde seria uma boa média para cada agrupamento que queríamos para cada face. Assume-se faces frontais e verticais na base de imagens. As coordenadas das médias foram calculadas e no final da análise de todo o conjunto de amostras, os valores médios foram calculados e adotados como médias iniciais para o processo de análise de agrupamentos. Na figura 3.(a), podemos verificar as médias inicias em uma face.
Foram implementados dois algoritmos de análise de agrupamentos, a saber: K-médias e Forgy, explicados resumidamente acima. Ainda assim, houve duas versões de implementação do algoritmo de K-médias e três do Forgy, considerando técnicas alternativas que serão relacionadas abaixo:
K-médias simples: Usa, para medida de distância o valor de distância euclidiana calculada entre o ponto e as médias. O algoritmo das k-médias é implementado seguindo as definições apropriadas;2.4 Exemplo ilustrativo
K-médias elaborado: Usa como medida de distância não só o valor da norma euclidiana, mas também o que chamamos de medida de forma (Dforma), a qual considera a forma que o agrupamento desejado deve ter. Por exemplo, no nosso caso, todos os agrupamentos tem formato elíptico. Portanto, essa medida toma como cálculo a diferença em x dos pontos mínimo e máximo de cada agrupamento (chamaremos de Dx), multiplicados por um certo peso p e subtraímos da diferença em y dos pontos mínimo e máximo (chamemos de Dy). Em termos matemáticos temos:

Como foi citado acima, a nova medida de similaridade é calculada levando-se em conta tanto a distância euclidiana como também a medida de forma. Em alguns algoritmos usamos pesos para cada uma delas, tentando assim dar maior consideração à uma distância ou à outra. A medida de forma foi usada novamente para as implementações do Algoritmo de Forgy. Vale lembrar que essa medida é calculada para cada agrupamento que queremos encontrar. A fórmula da distância para cada agrupamento i é dada por:

Forgy 1: A estratégia adotada nessa implementação foi apenas transpassar o K-médias elaborado para o método de Forgy. Ou seja, foi basicamente um reuso do código do algoritmo acima, considerando as alterações que eram necessárias quanto às médias dos agrupamentos para que o método que fosse implementado passasse a ser o de Forgy;Forgy - usando 2 agrupamentos: Essa implementação foi na verdade um passo intermediário para se chegar à próxima que foi uma nova técnica adotada. Aqui aplicamos o algoritmo de Forgy com apenas dois agrupamentos, colocados um próximo ao olho direito e outro no canto direito da boca da face analisada. Nosso objetivo aqui era conseguir reunir, no primeiro agrupamento, os dois olhos e no segundo, o nariz e a boca. Para isso, precisamos recalcular as taxas de erro que estávamos trabalhando para tornar os agrupamentos maiores, podendo assim incluir duas características importantes num único agrupamento. Vale lembrar que taxa de erro é o valor máximo que a distância de um ponto a um agrupamento-i pode assumir dentro daquele agrupamento. Se a distância do ponto ao agrupamento-i for menor que essa taxa de erro, o ponto é classificado como pertencente a este agrupamento.
Forgy - usando 4 agrupamentos: O processo desenvolvido aqui foi mais custoso em termos computacionais, mas os resultados foram, em média, melhores. O que se fez aqui é em uma primeira fase aplicar o mesmo processo da implementação anterior, ou seja, obtermos no final dois agrupamentos bem definidos, sendo um com olhos e outro com nariz e boca. Dada a imagem que foi obtida na separação desses dois agrupamentos iniciais, definimos quatro novas médias que serão usadas em uma segunda análise de agrupamentos usando apenas os pontos que obtivemos da primeira fase, o que já reduz a quantidade de pontos a serem analisados. Uma nota importante a ser considerada aqui é que tivemos que ter um controle muito mais rígido sobre as taxas de erro máximo sobre os agrupamentos. As coordenadas das novas quatro médias da segunda fase foram calculadas da mesma forma como antes, ou seja, através da análise de um conjunto de faces amostrais.
Para encerrar essa seção, ilustramos através
de figuras o que se obtêm como resultado das cinco implementações
aplicadas a uma mesma face, apenas para explicitar melhor o que foi discutido
até aqui. Inicialmente será exibida a face original e em
seguida a imagem com as bordas detectadas através do filtro de Sobel
considerando apenas os contornos horizontais (figura 3.b e 3.c).

(a)
(b)
(c)
Figura.3:
As médias iniciais estão mostradas em
(a); Imagem original (b) e o resultado do detector de bordas horizontais
de Sobel (c).
Comentamos que a escolha do detector de bordas horizontais de Sobel deveu-se ao fato deste ter fornecido bons resultados em relação aos prováveis agrupamentos de olhos nariz e boca que estudaremos nos algoritmos elaborados. Colocaremos agora os resultados que se obteve usando na mesma face da figura 3 os algoritmos de K-médias e o K-médias elaborado.


(a)
(b)
Figura 4:
Resultados obtidos usando-se respectivamente o K-médias
simples (a) e o K-médias elaborado (b), tendo como face a figura
3.b.
Pode-se ver pela figura 4 que para esta face, o algoritmo de K-médias elaborado determinou agrupamentos muito grandes, incluindo informações que não nos interessam, como cabelo, parte da orelha e da lateral direita da cabeça.
Agora colocaremos os resultados obtidos pelas três implementações do algoritmo de Forgy, começando pelo Forgy 1, apresentado na figura 5.

Figura 5:
Resultado obtido pelo Forgy 1 usando a face da figura 3.b
O único problema que surgiu para a detecção das características nessa face é que o agrupamento do nariz englobou a parte superior deste, que não nos interessa.
Para apresentar os algoritmos de Forgy usando 2 e 4 agrupamentos, exibiremos uma seqüência de figuras que mostrarão a evolução da detecção dos agrupamentos de acordo com o número de iterações que foram realizadas.
A implementação do Forgy usando 2 agrupamento utilizou 4 iterações para recálculo das 2 médias, enquanto o Forgy usando 4 agrupamentos gastou um total de 8 iterações, sendo as 4 iniciais devem-se à primeira fase do algoritmo que é o Forgy usando 2 agrupamentos e as 4 últimas à segunda fase que é a divisão em 4 agrupamentos através dos 2 inicialmente detectados.

Figura 6:
Iterações do Forgy usando 2 agrupamentos. De 1 a 4 estão exibidas como avançam o tamanho de cada um dos dois agrupamentos, identificados pelas cores azul claro e amarelo.
Na figura 7 mostra-se o resultado da detecção final desse algoritmo.

Figura 7:
Resultado do Forgy usando 2 agrupamentos para a face
da figura 3.b.
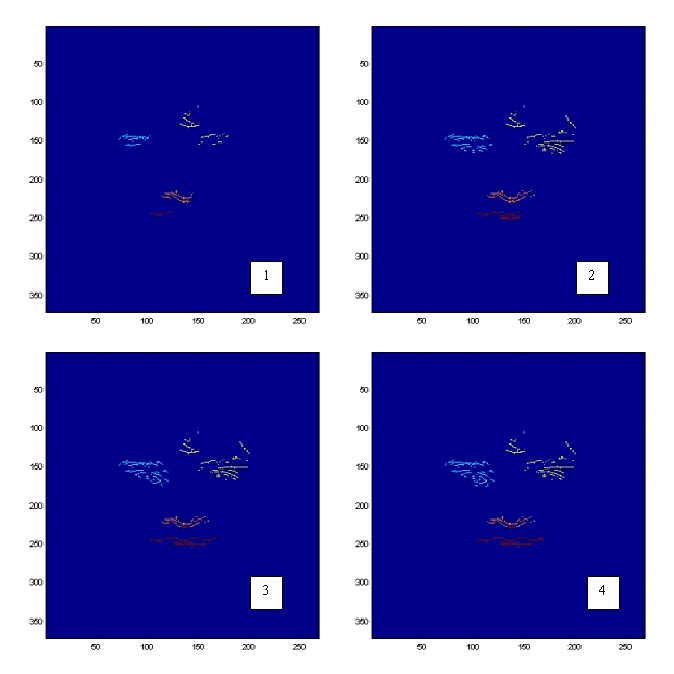
Figura 8:
Iterações do Forgy usando 4 agrupamentos.
De 1 a 4 estão exibidas como avançam o tamanho de cada agrupamento,
identificados pelas cores azul claro, amarelo, rosa e vermelho.
Para a face da figura 3.a e analisando o resultado obtido (figura 7), mesmo apesar do agrupamento superior conter grande parte da testa , classificamos esse resultado como bom, pois foi possível reunir nesse conjunto todos os pontos dos olhos.
Na figura 8, mostramos o resultado das iterações obtido usando a mesma face com a implementação do Forgy usando 4 agrupamentos. Para tanto, lembraremos que é apresentado apenas a segunda fase. A primeira, que consiste em encontrar os dois agrupamentos principais, resume-se exatamente a usar a técnica do Forgy usando 2 agrupamentos apresentado acima e cujo resultado encontra-se na figura 7 e as iterações na figura 6. Na figura 9 encontra-se o resultado da detecção desse algoritmo.

Figura 9:
Resultado da detecção dos 4 agrupamentos
usando o algoritmo de Forgy em 2 fases: a primeira encontra dois agrupamentos
principais e a segunda, separa esses dois em quatro.
A detecção nesse algoritmo conseguiu satisfazer provisoriamente nossos objetivos, pois parte da testa foi incluída no agrupamento do olho esquerdo, enquanto a parte inferior desse olho não. Isso deve-se à primeira fase do algoritmo, que não forneceu tão bom resultado.
Um ponto que deve merecer a atenção é que, para o Forgy usando 4 agrupamentos, o resultado final depende do conjunto de pontos que foi obtido após o término da primeira fase de análise de agrupamentos. Se esse conjunto conseguiu reunir nos dois agrupamentos iniciais todas as regiões de nosso interesse e sem detalhes secundários (testa, parte superior do nariz, queixo, barba), então podemos esperar que o produto final terá 4 agrupamentos bem definidos e cada um contendo informações sobre olho esquerdo ou direito ou nariz ou boca.
Considerando o conjunto das 5 implementações usadas nesse exemplo, podemos dizer que os melhores resultados para essa face foram obtidos com o K-médias simples e Forgy 1, pois os agrupamentos tiveram os menores tamanhos e continham, no mínimo, toda a informação que desejávamos.
Na próxima seção discutiremos os
resultados que foram obtidos, e também um teste como recomendação
que tivemos perante o julgamento do primeiro relatório.
3. RESULTADOS
3.1 Teste comparativo psicofísico
Seguindo as recomendações para melhoria do relatório dadas pelos assessores da Fapesp, decidimos comparar a detecção de características faciais feitas por humanos com a que se obtinha através da implementação do Kmédias elaborado.
Para explicar o processo realizado, vale lembrar que este é um teste psicofísico, pois o resultado final depende não mais do que foi computado, mas sim do que a pessoa escolhe como regiões válidas para os agrupamentos.
Foi desenvolvido um script em MatLab, que dada uma imagem,
pede para o usuário determinar, através de cliques do mouse,
as regiões que este considera como contendo olho direito, olho esquerdo,
nariz e boca, totalizando, assim, oito pontos (consideramos as regiões
como retangulares, bastam dois pontos distintos). Essa imagem é
guardada para ser comparada posteriormente. Além disso, convertemos
a imagem para binária, ou seja, agora a imagem só contém
pontos brancos ou pretos. Chamemos essa imagem de X1.
O próximo passo é passar a mesma imagem
original pelo algoritmo de K-médias elaborado, onde não há
nenhuma interação com o usuário que possa alterar
o valor das médias iniciais. O resultado é guardado. Chamemos
de X2 essa imagem que é gerada e convertida para binária.
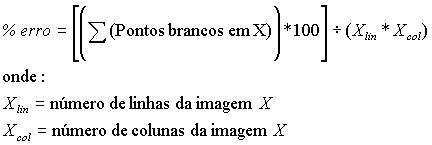
A comparação que decidimos fazer é
realizar uma operação comum em Processamento de Imagens denominada
subtração de imagens. No nosso caso, decidimos fazer módulo(X2
- X1), ou seja, subtrair da imagem resultado do k-médias elaborado
a que foi determinada pelo usuário, considerando o módulo,
pois a diferença entre as imagens pode gerar valores negativos para
as cores, que não são válidas. O resultado (X) é
uma nova imagem binária.
A medida de erro, que indica o quanto o programa se distanciou do que era aceitável, é calculada através da porcentagem de pontos não pretos que se encontram em X. Para tanto, somamos todos os pontos em X que tem cor branca. De posse desse valor, multiplicamos por 100 e, em seguida, dividimos pelo tamanho da imagem, fornecendo uma porcentagem de pontos brancos encontrados. A fórmula pode ser encontrada abaixo:
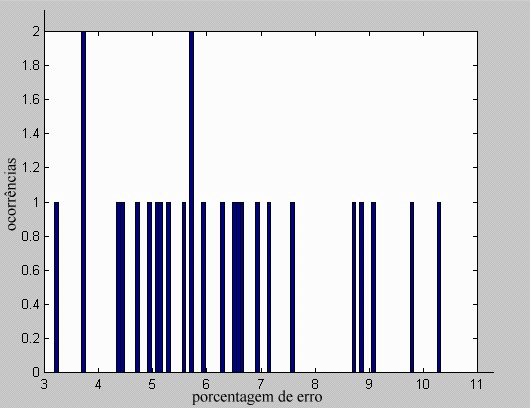
Um valor muito alto para a porcentagem de erro significa que o resultado do algoritmo se distanciou muito do que era aceitável para aquele usuário. Enquanto uma porcentagem baixa mostra um acerto considerável do algoritmo em relação às regiões que se desejam encontrar. Vale lembrar que o valor retornado depende muito das regiões que o usuário determina como sendo viáveis para os quatro agrupamentos. Na figura 11 encontra-se um exemplo de separação de agrupamentos feita manualmente.
Esse teste foi realizado várias vezes, considerando usuários com consciência da determinação correta dos agrupamentos, ou seja, não foi determinado um agrupamento para o olho direito que se localiza na região da testa, por exemplo. Em média, os erros que se calcularam ficaram em torno de 5% a 7,8%. Qualquer valor acima dessa faixa indica que o distanciamento entre o algoritmo de K-médias elaborado e o ideal foi grande. Além disso, o que foi detectado provavelmente poderia não contém todas as características que nos interessam.
Foram usadas como teste 26 faces incluindo homens e mulheres com rostos risonhos e sérios, e uma com diferença de iluminação. Foi calculado um histograma dos erros que essas faces geraram em um dos testes realizados, visto na figura 10. Para o teste usado para gerar o histograma da figura, o valor exato da média dos erros foi 5,874 %. Ou seja, em média, para cada uma das 26 faces do teste, o algoritmo de K-médias elaborado se distanciou 5,874 % do resultado que queríamos obter.
Assim, podemos dizer que os resultados foram satisfatórios
estatisticamente. Entretanto, é desejável o desenvolvimento
de um algoritmo de ajuste mais fino, o que deverá ser feito como
pesquisa futura.
3.2 Resultados obtidos com os cinco algoritmos implementados
Para explicar os resultados, haverá uma subseção
para cada algoritmo implementado. É bom lembrar que a base de imagens
utilizada já tinha sido definida antes da implementação
de qualquer um destes algoritmos. Todos os tempos que forem citados foram
calculados em um computador Pentium MMX 200 MHz com 32MB de memória
RAM em ambiente Windows. Outro ponto a considerar é que todos utilizaram
Sobel como detector de bordas, considerando apenas as bordas horizontais,
por ser mais rápido, e que se desenvolveu melhor nos primeiros algoritmos
implementados.
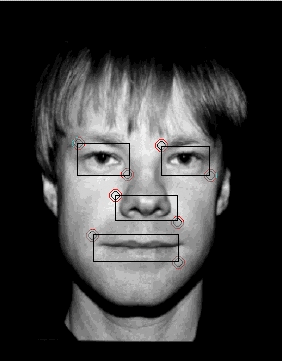
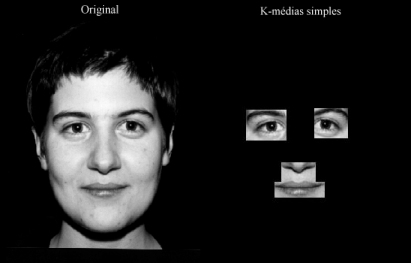
3.2.1 K-médias simplesEsse algoritmo teve 5 iterações para recalcular as posições das médias e o tempo médio que gastou para analisar uma face é aproximadamente de 11 a 18 segundos.O ponto forte desse algoritmo foi, além da rapidez em comparação com os outros, a capacidade de conseguir englobar, nos quatro agrupamentos, todas as características que nos interessavam, na grande maioria das vezes.
O ponto negativo é que, em vários casos, os agrupamentos determinados continham muita informação desnecessária da face analisada (por exemplo, cabelo, testa, barba, parte superior do nariz). Na figura 12, temos o resultado desse algoritmo onde encontramos regiões maiores do que nos interessavam.
Podemos ver, por esse exemplo, que regiões como parte superior do nariz, uma parte pequena da orelha, bigode, parte do queixo e barba foram consideradas como pertencentes a algum dos quatro agrupamentos, não sendo do nosso interesse detectá-los.
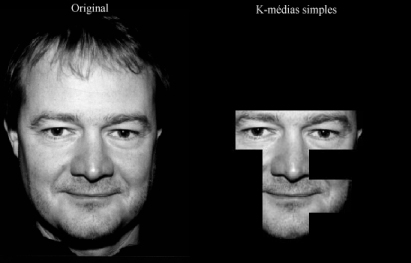
3.2.2 K-médias elaborado
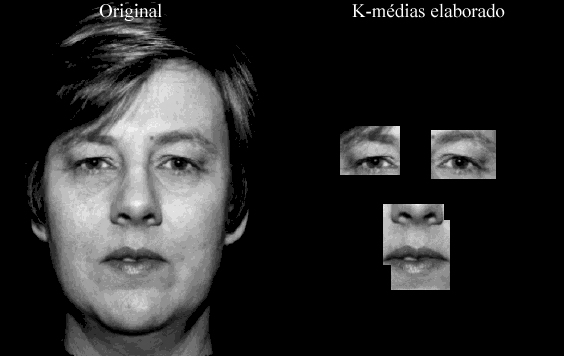
Na figura 13 temos um bom exemplo de detecção das características que queremos achar.Vemos aqui um ótimo resultado que conseguimos obter utilizando o K-médias simples, caracterizado principalmente pelo tamanho pequeno dos agrupamentos. Vale ressaltar algo que aconteceu muito freqüentemente em praticamente todos os algoritmos implementados, que foi a sobreposição dos agrupamentos do nariz e da boca. Isso deve-se à taxa de erro máximo adotada para os agrupamentos, contudo isso não vem a atrapalhar o resultado final, desde que sejam encontrados nariz e boca.
Esta implementação utilizou apenas uma iteração, devido à alta complexidade em relação ao tempo de processamento. Enquanto o K-médias simples demorava, em média, um total de 18 segundos, este leva de 25 a 40 devido a dois fatores principais:MODULARIZAÇÃO: Operações como abrir a imagem e detectar as bordas, mudar o valor da média durante cada amostra que está sendo analisada, recortar na imagem original os agrupamentos que foram detectados pelo algoritmo e o cálculo das distâncias de um ponto a todas as quatro médias usadas foram transformadas em funções. Uma parcela desse aumento do tempo gasto advém do custo computacional em se interromper o programa principal, guardar o seu estado de execução e ficar invocando essas funções auxiliares, principalmente a responsável pela mudança da média a cada ponto classificado como pertencente a um agrupamento k.
PADRONIZAÇÃO DO TAMANHO DA IMAGEM: Para tornar o algoritmo mais abrangente, a partir dessa implementação, resolvemos inserir um pequeno código MatLab com o objetivo de que, dada uma imagem em tamanho qualquer, esta seja redimensionada para um tamanho padrão. Além desse processo, foi preciso aplicar à imagem original um filtro de correção para retirar os ruídos que são gerados em um processo de redimensionamento. Escolhemos o filtro de interpolação bilinear, pois conseguimos reduzir muito a perda de informação na nova imagem gerada. Além disso, esta filtragem já se encontra presente no MatLab.
O problema de modularização ocorreu exatamente na separação em funções para os cálculos de distância e mudança de uma k-média, uma vez que essas operações são, em geral, refeitas a cada ponto examinado na imagem.
O ponto forte desse algoritmo reside no fato que, para algumas imagens testadas, o resultado obtido é muito preciso, mesmo acontecendo o problema de sobreposição dos agrupamentos de nariz e boca. Na figura 14 podemos ver um bom resultado.
No entanto, as desvantagens dessa abordagem são duas:1. Tempo computacional gasto, devendo-se à forma como o algoritmo foi implementado e explicado acima.2. Para algumas faces, o resultado retornado é muito ruim, devido à má sintonização dos parâmetros. Nesses casos, o tempo consumido tende a ser até superior a 40 segundos.
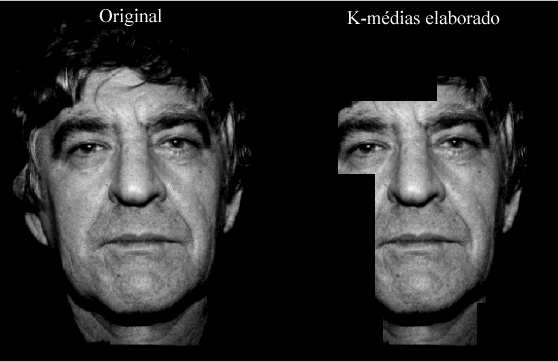
Na figura 15, encontramos um exemplo como descrito no item 2 acima, gastando 31,6 s. O problema que ocorreu para o exemplo acima tem um motivo: A detecção de bordas por Sobel horizontal nesta face retorna um conjunto com muitos pontos ao redor da boca, devido à barba .
O resultado da detecção de bordas pode ser conferido na figura 16. Percebe-se que, ao redor dos agrupamentos principais desejados, há muitos pontos que surgiram ou de rugas, ou de pêlos da face (barba, bigode e cabelos). Pode-se notar que as sobrancelhas foram totalmente detectadas, o que já contribui para o aumento dos agrupamentos dos olhos. Assim, o conjunto de pontos que o algoritmo terá que tratar será muito maior, aumentando o tempo gasto e o tamanho dos agrupamentos, uma vez que esses se baseiam simplesmente em similaridade através de distância, não levando em conta o número máximo de pontos por agrupamento.

3.2.3 Forgy 1
Esta implementação, baseada no K-médias elaborado, realiza duas iterações, gastando entre 18 e 35 segundos devido aos mesmos fatores citados na seção 3.2.2. Vantagens dessa implementação incluem o fato que, para imagens que antes retornavam resultados muito ruins, tal como na figura 15, os agrupamentos agora aparecem bem definidos. Além disso, comparando com o K-médias elaborado, os resultados retornados foram mais apurados em termos de definição correta dos agrupamentos e respostas mais rápidas.Na figura 17 encontra-se o resultado obtido com o Forgy 1 na face da figura 15, o que consumiu um tempo de 23,18 s, nas mesmas condições que o teste realizado com o K-médias elaborado.

A desvantagem desse algoritmo é devido à uma limitação no número de iterações, pois o algoritmo de Forgy propõe que haja no mínimo 2 iterações mas não há um limite superior definido. Precisamos impor um valor máximo para as iterações, caso contrário o programa pode não encontrar um caminho de finalização.Uma conseqüência desse problema é acarretada na definição dos agrupamentos, pois se as médias iniciais não caírem dentro das regiões de interesse, os agrupamentos que serão formados ao final do algoritmo podem muito certamente não conter toda a informação que queremos, devido ao baixo número de iterações. Na figura 18, colocamos um exemplo em que a face está um pouco fora das definições iniciais das médias que adotamos.
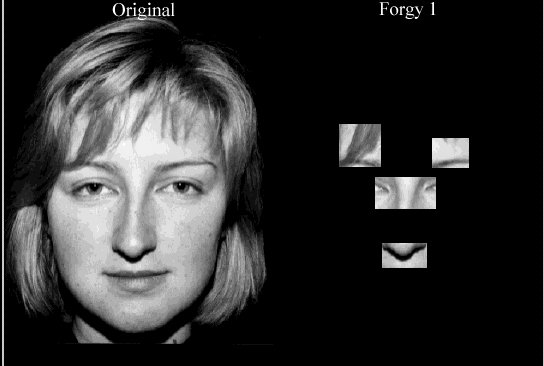
3.2.4 Forgy - usando 2 agrupamentosPercebe-se que os agrupamentos não conseguiram englobar nenhuma informação que desejávamos. Poderíamos até comentar que no último agrupamento de cima para baixo encontram-se as duas narinas, que são informações que queremos, mas esse agrupamento é destinado à boca.Nessa implementação ocorrem 4 fases de reclassificação de pontos. O resultado desse algoritmo não deve ser considerado como principal, pois nosso objetivo é encontrar quatro regiões com as características da face. Contudo, levando-se em conta que o próximo algoritmo usa este para conseguir detectar os agrupamentos finais, se este falhar ao determinar as 2 regiões, o Forgy usando 4 agrupamentos provavelmente falhará.O tempo gasto com essa implementação está em torno de 35 a 48 segundos.
Na figura 19 encontra-se um exemplo em que há boa determinação dos dois agrupamentos que queremos achar.
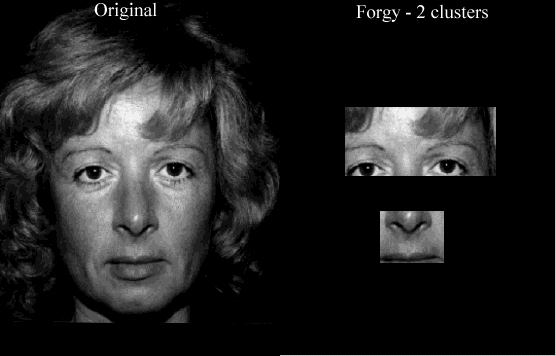
O ponto fraco dessa implementação é que para algumas faces, os agrupamentos determinados não conseguem englobar as duas características que devem pertencer a cada um. Por exemplo, na figura 20 está um exemplo onde no resultado temos o agrupamento dos olhos contendo apenas o olho direito. Para este exemplo, o Forgy usando 4 agrupamento retornará resultado errado.
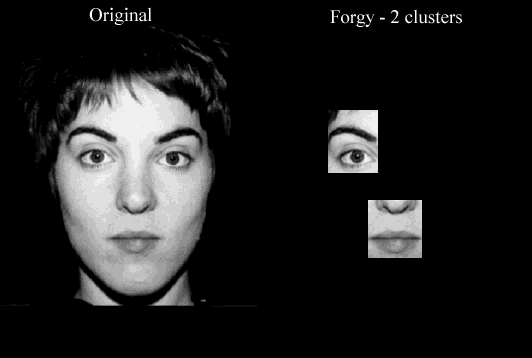
3.2.5 Forgy - usando 4 agrupamentos
Como foi dito anteriormente, se o Forgy - 2 agrupamentos falhar, então esse algoritmo também falhará, pois este é dependente do conjunto de pontos que recebe. O tempo gasto por esse algoritmo tende a ser em torno de 55 a 70 segundos, lembrando que ao todo são feitas 8 reclassificações de pontos (4 na primeira fase, que é o Forgy usando 2 agrupamentos e mais 4 com os pontos que este retorna).Na figura 21 colocamos um exemplo onde os quatro agrupamentos conseguem ser bem identificados, mas isso deve-se ao resultado obtido na primeira fase, também mostrado.
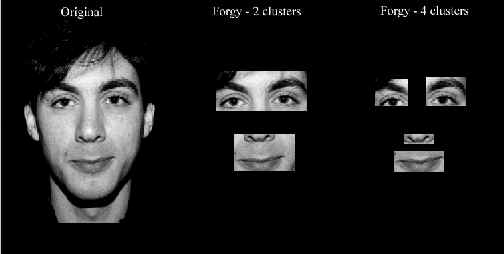
Na próxima seção desenvolve-se um breve comentário sobre possíveis melhoramentos que podem ser feitos, indicando também prováveis caminhos alternativos para se contornar os problemas atuais.
Agora mostraremos o que acontece quando o resultado do Forgy - 2 agrupamentos é errado. Usaremos para isso a mesma face original encontrada na figura 20, na qual também é possível ver os dois agrupamentos que são identificados inicialmente.

Figura 22:
Devido aos dois agrupamentos iniciais, o resultado final ficou prejudicado para a face da figura 20.A principal desvantagem dessa abordagem deve-se ao fato da dependência em relação à primeira fase ser muito grande, o que pode ser visto comparando-se as figuras 20 e 22. Além disso, o tempo gasto é alto, ainda mais para se obter um resultado que nem sempre é o desejável.
4 CONCLUSÃO
4.1 Resumo
Nesta seção faremos comentários gerais
sobre os métodos que adotamos para o problema de reconhecimento
de faces, bem como proporemos meios de torná-los um pouco melhores
em termos de análise de agrupamentos e medidas de similaridades.
4.2 Comentários gerais
Começaremos a discussão pelos programas
que utilizam como técnica a análise de agrupamentos por K-médias.
4.2.1 K-médias simples:
Para o K-médias simples que utilizava 5 iterações e durava um tempo estimado em 18 segundos, podemos dizer que o resultado tende a ser pior quando a pessoa possui franjas, sobrancelhas muito grandes ou barba por fazer. A ocorrência de uma dessas características na face original produz um resultado muito maior na quantidade de pontos que são detectados como contornos pelos detectores de bordas em geral, não somente pelo que adotamos (método de Sobel).
Sendo assim, uma melhora que pode ser feita é um
pré-processamento sobre cada face que será analisada. Com
isso, para cada face usa-se antes do K-médias simples um filtro
para eliminar ruídos [veja 5 e 6, para mais informações],
que constituem em pêlos de barba, detalhes da face, como pintas,
e outros. O importante é que as características principais
da face serão mantidas, não atrapalhando em nada o funcionamento
do processo de análise de agrupamentos feito pelo K-médias
simples. Se pensarmos em termos de pontos, a filtragem feita provoca uma
redução no número de elementos desse conjunto, o que
permitirá ao detector de bordas ser mais rápido na sua análise
e reduzir, ou até mesmo eliminar, detalhes que haviam na face original.
Contudo, o tempo aumentará em aproximadamente 10
segundos para o processo completo ser realizado (pré-processamento
através de filtragem da face + K-médias simples). O pré-processamento
indicado aqui é uma de várias formas que podem ser feitas
para melhorar o resultado final desse algoritmo.
4.2.2 K-médias elaborado:
Vimos na seção 3.2.2 os motivos que tornaram essa implementação mais lenta. Quanto à parte de padronização da imagem inicial, não há muito o que mudar, pois é necessário que dada uma imagem em tamanho qualquer, o algoritmo consiga determinar os agrupamentos de nosso interesse. Não se pode prender a funcionalidade da algoritmo ao tamanho da imagem de entrada.
Quanto à modularização, pode-se tentar fazer o processo inverso, ou seja, para as funções que são mais requisitadas dentro do laço principal do programa, talvez seja melhor incluir o código que seria executado por estas diretamente no programa principal, eliminando custos computacionais de chamadas de funções, que provocaram o grande aumento no consumo de tempo.
Em princípio, as funções que precisariam ser eliminadas seriam a de mudança da média do agrupamento e do cálculo da distância do ponto a todos os agrupamentos. Ainda assim, a função que calcula a distância tem maior número de requisições, uma vez que, para cada ponto do conjunto a ser classificado, precisa ser feita uma chamada a esta. No entanto, a função responsável pela alteração da média é invocada somente quando um ponto é realmente classificado como pertencente à algum agrupamento.
Com as medidas descritas acima, conseguimos reduzir um pouco o tempo gasto com essa implementação.
Como essa implementação segue o mesmo princípio
do K-médias simples, o problema que ocorria quanto aos detalhes
na face original também aparece aqui. Para resolvê-lo, também
seria válida a possibilidade de se fazer uma fase de pré-processamento
como descrita na seção 4.2.1.
4.2.3 Forgy 1:
O Forgy 1 utiliza apenas duas iterações e, como foi uma adaptação do K-médias elaborado para que utilizasse o método de Forgy, as recomendações comentadas na seção 4.2.2 quanto à padronização e à modularização são válidas aqui também. Contudo a fase de pré-processamento pode ser feita apenas para faces que tenham uma quantidade muito grande de detalhes pois, como pode ser visto na figura 17, a mesma figura que provocou resultados ruins nos algoritmos de K-médias, passou muito bem pelo Forgy1, mesmo tendo a face inicial detalhes de barba.
Assim, a fase de pré-processamento deve apenas
ser realizada quando soubermos, de antemão, que o conjunto de faces
a serem testadas pelo algoritmo possuem grandes quantidades de detalhes
de face; caso contrário, será consumido tempo praticamente
desnecessário, pois o método de Forgy consegue reduzir o
efeito que detalhes simples da face possam provocar no agrupamento.
4.2.4 Forgy usando 2 agrupamentos
Como o objetivo dessa implementação é a detecção de apenas 2 grandes agrupamentos, o problema que pode ocorrer é na definição do ponto da média de um agrupamento ki , e agregado a isso está também a taxa de erro que mantém o tamanho deste agrupamento.
A existência de erro na média de um agrupamento ou na taxa de erro pode provocar a determinação errada deste. Pelos testes que realizamos não conseguimos chegar a um ponto padrão para ser usado como média em algum dos 2 agrupamentos. Se fosse possível obter esse ponto, a taxa de erro mais apropriada poderia ser inferida pelos próprios testes. O resultado final poderia ser muito mais correto, evitando problemas como o que ocorreu na figura 20.
Considerando que o Forgy usando 4 agrupamentos depende do resultado desse algoritmo, torna-se importante melhorar a construção dos dois agrupamentos iniciais.
Quanto ao tempo, como este consome um certo número
de iterações, há uma relação inversamente
proporcional entre resultado e tempo gasto. Se quisermos um bom resultado,
teremos que pagar por uma quantidade mais elevada de iterações
do laço principal.
4.2.5 Forgy usando 4 agrupamentos:
Como foi comentado anteriormente, o bom resultado de detecção obtido por esse algoritmo depende claramente da imagem retornada pelo Forgy usando 2 agrupamentos.
Para analisar o que pode ser melhorado nesse algoritmo, suponhamos que o resultado obtido pelo Forgy usando 2 agrupamentos contém realmente as informações de olhos e nariz e boca agrupados separadamente.
Nessa implementação precisamos fazer uma
alteração quanto ao peso usado na distância da forma
dos 4 agrupamentos a serem encontrados. Essa modificação
teve como pretensão reduzir o tamanho de cada um dos agrupamentos,
especialmente entre os do nariz e boca devido a sua proximidade um do outro.
Porém, há uma vantagem e uma desvantagem com essa alteração:
Vantagem: Se a imagem com os dois agrupamentos
iniciais estiver bem definida, os 4 agrupamentos finais encontrados por
essa implementação tende a serem pequenos e com toda a informação
que queremos que cada um tenha.
Desvantagem: Como a boca não tem um tamanho
definido, o agrupamento detectado no final pode não contê-la
por completo. Isso muitas vezes é corrigido através do número
de iterações que o programa faz. Aumentando-o, a média
do agrupamento da boca tende a ser transladada para a direita, possibilitando
a classificação de mais pontos como sendo da boca.