A montagem do espelho consistiu na importação de um subconjunto da base de dados do Genbank para o nosso espelho (uma estação de trabalho Sun com gerenciador de banco de dados Sybase). Essa base de dados é disponibilizada em arquivos denominados flat files que possuem uma série de entradas no formato Genbank Flat File Format. Cada entrada representa uma sequência de DNA e além da sequência em si contem uma série de informações extras. Um exemplo de entrada dos flat files pode ser visto abaixo:
LOCUS AAB2MCG1 289 bp DNA PRI 06-JUL-1998
DEFINITION Aotus azarai beta-2-microglobulin precursor, gene, exon 1.
ACCESSION AF032092
VERSION AF032092.1 GI:3265027
KEYWORDS .
SEGMENT 1 of 2
SOURCE Azara's night monkey.
ORGANISM Aotus azarai
Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi;
Mammalia; Eutheria; Primates; Platyrrhini; Cebidae; Aotinae; Aotus.
REFERENCE 1 (bases 1 to 289)
AUTHORS Canavez,F.C., Ladasky,J.J., Muniz,J.A.C., Seuanez,H.N., Parham,P.
and Cavanez,F.C.
TITLE beta2-Microglobulin in neotropical primates (Platyrrhini)
JOURNAL Immunogenetics 48 (2), 133-140 (1998)
MEDLINE 98298008
REFERENCE 2 (bases 1 to 289)
AUTHORS Canavez,F.C., Ladasky,J.J., Seuanez,H.N. and Parham,P.
TITLE Direct Submission
JOURNAL Submitted (31-OCT-1997) Structural Biology, Stanford University,
Fairchild Building Campus West Dr. Room D-100, Stanford, CA
94305-5126, USA
FEATURES Location/Qualifiers
source 1..289
/organism="Aotus azarai"
/db_xref="taxon:30591"
exon <134..200
/number=1
sig_peptide 134..193
intron 201..>289
/number=1
BASE COUNT 30 a 99 c 80 g 80 t
ORIGIN
1 gtccccgcgg gccttgtcct gattggctgt ccctgcgggc cttgtcctga ttggctgtgc
61 ccgactccgt ataacataaa tagaggcgtc gagtcgcgcg ggcattactg cagcggacta
121 cacttgggtc gagatggctc gcttcgtggt ggtggccctg ctcgtgctac tctctctgtc
181 tggcctggag gctatccagc gtaagtctct cctcccgtcc ggcgctggtc cttcccctcc
241 cgctcccacc ctctgtagcc gtctctgtgc tctctggttt cgttacctc
//
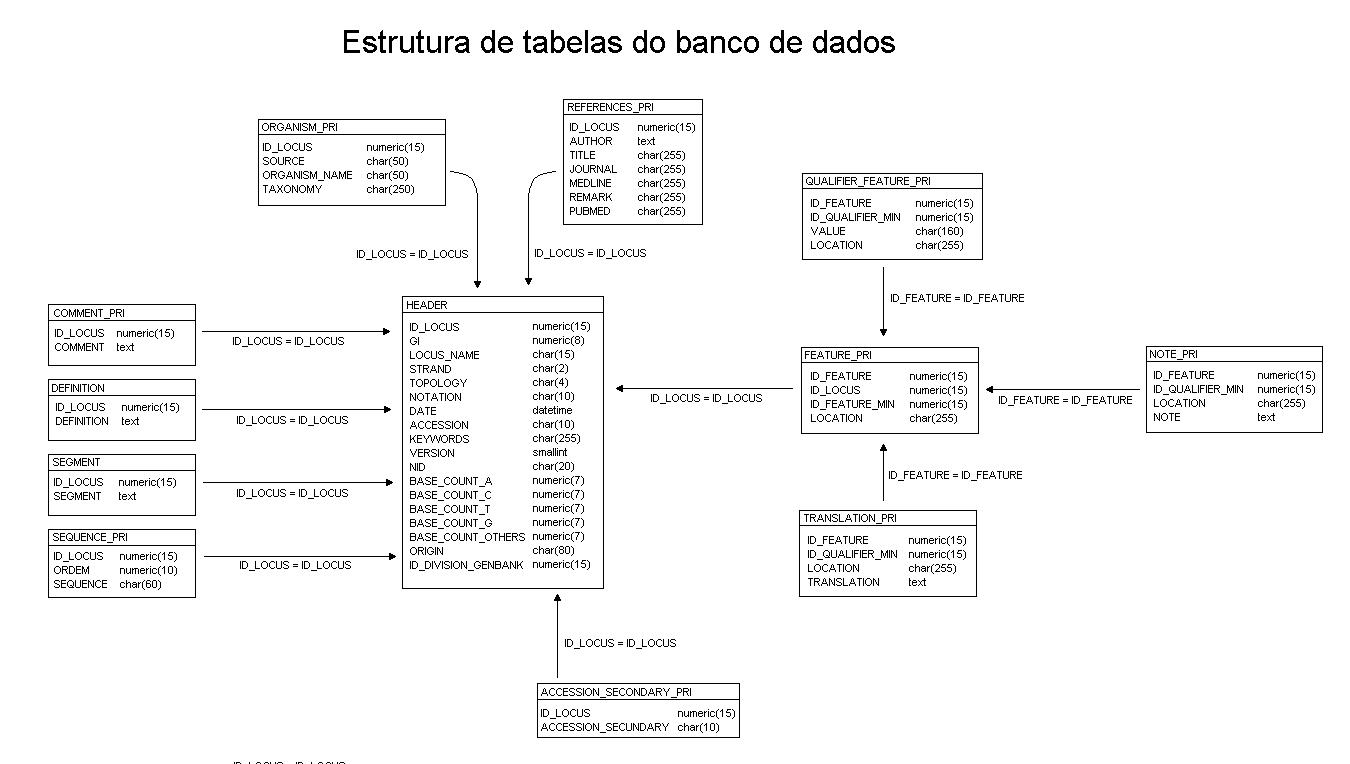
Entretanto o formato como as entradas são disponibilizados pelo Genbank não é apropriado para ser armazenado diretamente num banco de dados. Por isso foi criada uma estrutura de 12 tabelas com o objetivo armazenar as informações contidas nas entradas de forma apropriada no banco de dados do espelho (clique aqui para ver a estrutura de tabelas).
Com isso surgiu a necessidade de se criar um sistema que processasse os dados dos flat files e fizesse a inserção desses dados processados no banco de dados do espelho. Foi ai que entrou a minha participação no projeto, desenvolvendo esse sistema de processamento e carga dos flat files.
No início do projeto, após a exposição dos objetivos e das minhas tarefas, a primeira coisa que fiz foi ler uma documentação especificando o formato dos flat files. Era uma documentação disponibilizada pelo próprio Genbank que explicava todos os campos encontrados nas entradas dos flat files: os valores contidos em cada campo, o tamanho máximo de cada campo em linhas (no caso de haver um limite), se um campo era obrigatório ou não (isto é, se ele tem que aparecer em todas as entradas dos flat files ou não necessariamente).
Embora a documentação não fosse muito extensa e de modo geral a estrutura das entradas dos flat files fosse estável, tive que estudar esse documento com muita atenção pois um entendimento por completo era necessário para que o processamento dos arquivos se desse da forma correta e sem erros. Por isso, mesmo depois desse estudo inicial, esse documento foi constantemente consultado durante todo o desenvolvimento do projeto.
Algum tempo depois do início do projeto, outro tema de estudo abordado foi o sistema gerenciador de banco de dados Sybase. Embora não tenha sido efetivamente um estudo, o Márcio me deu uma série de dicas e explicações sobre o Sybase, incluindo ai as ferramentas de gerenciamento do banco de dados (tanto nas versões windows, quanto nas versões Unix). Essas dicas e explicações me foram muito úteis, além de ser o meu primeiro contato com um sistema de banco de dados onde foi possível ver na prática uma série de tópicos discutidos na disciplina de Banco de Dados.
Finalmente, o último tema de estudo foi a biblioteca Rogue Wave (para C++) usada para fazer a comunicação de programas com o banco de dados. Nesse estudo aprendi a ultilizar as funções da biblioteca para: estabelecer conexão de um programa ao banco de dados; executar consultas SQL; executar stored procedures (coisas que até então eu tinha uma noção teórica de como se fazia, mas nunca havia feito na prática).
Como visto acima, para que os dados fornecidos pelos flat files pudessem ser inseridos na base de dados foi necessário converter o formato original dos arquivos para o formato correspondente às tabelas do banco de dados. Mais explicitamente, cada entrada do flat file (representando uma sequência de DNA e informações adicionais sobre essa sequência) teve que ser particionada em registros, onde cada novo registro correspondia a uma entrada em alguma das 12 tabelas do BD, conforme a informação que esse novo registro representava.
Por exemplo, para a entrada do flat file mostrada como exemplo acima teríamos:
3023 Azara's night monkey. Aotus azarai Eukaryota; Metazoa; (...) Aotinae; Aotus.
3023 1 gtccccgcgggccttgtcctgattggctgtccctgcgggccttgtcctgattggctgtgc 3023 2 ccgactccgtataacataaatagaggcgtcgagtcgcgcgggcattactgcagcggacta 3023 3 cacttgggtcgagatggctcgcttcgtggtggtggccctgctcgtgctactctctctgtc 3023 4 tggcctggaggctatccagcgtaagtctctcctcccgtccggcgctggtccttcccctcc 3023 5 cgctcccaccctctgtagccgtctctgtgctctctggtttcgttacctc
Note que o o primeiro campo em ambas as tabelas (ID_LOCUS) seria no caso um identificador para a entrada do exemplo.
O parser faz a leitura de um flat file, linha a linha, e para cada entrada contida no arquivo o programa gera os registros correspondentes uma das 12 tabelas do BD. Cada registro gerado é armazenado em um arquivo em disco correspondente à tabela na qual o registro será inserido. Dessa forma quando o parser é executado ele cria 12 arquivos em disco, cada um representando uma tabela do banco de dados, e cada linha desses arquivos representando um registro da tabela correspondente. Como separador de campos dessas linhas é usando o caractere TAB.
Depois de gerados, os conteúdos desses 12 arquivos podem finalmente ser inseridos nas tabelas correspondentes no nosso espelho, e assim a base de dados vai sendo incrementada com os dados provenientes do flat file processado.
Mas por que gerar esses arquivos correspondentes a cada tabela do BD em disco e depois inserir os dados de uma vez, ao invés de simplesmente ir inserindo os dados conforme cada registro de uma tabela fosse gerado? Por que aparentemente criar uma etapa intermediária nesse processo de processar as entradas de um flat file e inserir os dados gerados no banco de dados?
A razão para isso é que fazer uma inserção dos dados usando insert para cada registro gerado seria inviável pois seria um processo muito lento. E não podemos esquecer que estamos lidando com uma quantidade de dados muito grande, cada flat file tem em média 200 megabytes e no total são mais ou menos 120 flat files para serem processados.
A solução para inserir os dados na base rapidamente é fazer uma carga rápida. Ou seja, carregar de uma vez os dados nas tabelas (processo chamado de bulkcopy, algo como "copia em atacado"). Eis aí a razão de se gerar os arquivos correspondentes às tabelas em disco. Depois que eles são gerados, eles são inseridos no banco de dados atráves de um bulkcopy. Mais especificamente no Sybase (o gerenciador de banco de dados do espelho), atráves do comando bcp que carrega os dados de um arquivo formatado para uma tabela do BD.
Abaixo tempos um esquema do funcionamento do parser, mostrando os arquivos gerados e a carga dos arquivos para o banco de dados. Além disso vemos que o parser faz alguns acessos ao banco de dados, o que será discutido logo abaixo.
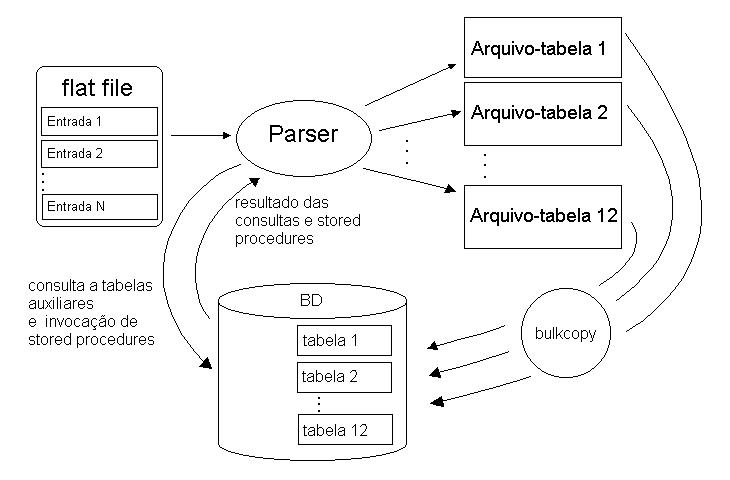
Dessa forma, o parser, antes de começar a processar uma nova entrada do flat file, tem que se conectar ao banco de dados e invocar a execução da stored procedure responsável pela geração do ID_LOCUS. Analogamente no processamento de uma entrada do flat file, quando vamos processar uma nova feature chamamos outra stored procedure a fim de se gerar um novo ID_FEATURE.
Ambas as stored procedures funcionam da mesma maneira. No banco de dados existem duas tabelas (uma para o ID_LOCUS e outra para o ID_FEATURE) cada uma com uma única coluna que contem apenas um registro que é o valor do próximo id a ser gerado. Quando o parser invoca uma stored procedure, esse valor é lido e armazenado, o valor do id na tabela é incrementado, e finalmente o valor armazenado é devolvido para o parser.
Dessa forma, durante o processamento dos flat files, quando lemos algum valor que se encaixa no caso acima explicado, temos que descobrir o identificador numérico correspondente ao valor. Para isso o parser mantem em memória essas tabelas auxiliares que associam valores a identificadores numéricos, mas, sempre que o parser começa a ser executado, ele acessa o banco de dados para carregar essas tabelas auxiliares.
Como pode ser visto no roteiro acima, após o flat file ser processado e antes dos dados serem carregados para o banco de dados, é feita uma verificação de erros nos arquivos gerados pelo parser. Para realizar essa verificação implementei um script em Perl cuja função era detectar erros nas tabelas geradas pelo parser. Esse script lia a definição de uma tabela do BD, e depois carregava o arquivo de dados correspondente a essa tabela, verificando linha a linha se cada registro estava de acordo com a estrutura da tabela. Esse programa foi muito útil para achar erros nos arquivos gerados e localizar as entradas dos flat files que não tinham sido processadas corretamente para que eu pudesse corrigir os problemas (isso ainda durante a fase de desenvolvimento e testes do parser).
Além disso, depois que os dados são carregados para a base, fazemos também a limpeza do log do gerenciados de banco de dados, através de um shell script responsável por essa tarefa. Isso porque a quantidade de dados processados e carregados para a base era tanta que se não limpassemos o log entre o processamento de um arquivo e o próximo, o tamanho do log podia chegar facilmente no limite máximo, paralisando o BD, e consequentemente paralisando todo o processamento dos arquivos (isso inclusive me rendeu umas dores de cabeça discutidas mais abaixo nas dificuldades).
Como resultado final desse meu estágio, concluí todo o sistema de processamento de flat files e de carga de dados no espelho. Ou seja, tinhamos agora uma ferramenta pronta para fazer a importação da base de dados do Genbank, que automatizava todas as tarefas necessárias para isso. Logo depois de ter concluído o sistema, foram feitos ainda mais alguns testes e finalmente o colocamos para rodar e procecessar todos os flat files que seriam importados para o banco de dados do espelho, ocorrendo tudo como esperado (depois de dois dias de processamento).
Logo depois disso, eu sai desse estágio no laboratório de banco de dados (para estagiar numa empresa, pois queria ver como é o mercado de trabalho num ambiente fora da universidade) me desligando desse projeto. O espelho em si ainda não estava pronto nessa época, pois havia a parte do site também para ser feita na qual havia uma outra pessoa trabalhando. Entretanto hoje o espelho está quase pronto e em pouco tempo deve entrar no ar.
A maior dificuldade (e também o maior desafio) encontrado nesse projeto foi lidar com o volume enorme de dados a serem processados. A grande quantidade de informações tornava o processo de debug de todo o sistema algo não muito simples.
Desenvolvi praticamente todo o parser usando umas 5 ou 6 entradas retiradas de alguns flat files e só quando o parser estava já num estágio bem avançado de desenvolvimento que comecei a testá-lo para arquivos maiores. Foi nesse momento que o debug começou a ficar complicado, pois a variedade de possíveis entradas contidas nos flat files é enorme (embora o formato das entradas seja bem definido) e começaram a surgir alguns casos de entrada que o parser não tratava direito. Aliado a isso temos o fato de que testes maiores, isto é, processando uma quantidade maior de dados, demoravam muito para serem executados, o que reduzia o rendimento da caça aos bugs.
Uma forma de enfrentar esse problema, foi desenvolver o script em Perl que verificava os arquivos gerados pelo parser. Esse script foi uma valiosa ferramenta de debug pois me permitiu localizar com mais facilidade as entradas que não estavam sendo processadas corretamente e corrigir os problemas encontrados. Além disso, uma outra saída para detectar e localizar casos de erro foi fazer a análise dos arquivos de log gerados tanto pelo parser, quanto pelo script de carga de dados.
Um epsódio particular de uma dificuldade que eu enfrentei foi a primeira vez que o log do banco de dados estourou. Aconteceu alguns dias depois que eu comecei testar o parser com entradas maiores (pois até então o log do banco de dados crescia num ritmo muito mais lento). Eu havia disparado o parser para processar um flat file e como ia demorar um pouco para terminar a execução e já estava na hora de ir embora deixei o parser rodando em background. Quando no dia seguinte fui verificar o resultado do processamento, notei que o programa não tinha acabado de executar ainda e que ele estava aparentemente travado pois os arquivos-tabela gerados pelo parser não estavam mais aumentando de tamanho. Até ai tudo certo, pois poderia ser um erro do programa que tivesse feito o programar entrar num loop infinito, ou algo do tipo. Entretanto quando matei o parser em execução e mandei ele rodar novamente, para a minha surpresa ele ficou paralisado logo no processamento da primeira entrada do flat file. Investigando o parser, cheguei a conclusão que o problema acontecia quando o programa ia se comunicar com o banco de dados. Não entendendo o por que de tudo isso, abri uma ferramenta de gerenciamento do BD para tentar acessar os dados manualmente mas nada. O banco de dados não respondia. Nesse momento então eu comecei a ficar realmente preocupado com medo de que pudesse ter danificado o banco de dados, tomei um grande susto. Entretanto quando conversei com o Márcio sobre isso ele logo percebeu do que se tratava, ou seja, o fato de o log do banco de dados ter estourado paralisando o funcionamento do BD.
Além das dificuldades acima, tiveram outras também, porém num grau menor de importância. A dificuldade em lidar com um programa/linguagem/tecnologia nova. No meu caso especifico a familiarização com o Sybase e a aprendizagem de uso da biblioteca Rogue Wave. Mas nada que um pouco de estudo, ou umas dicas não ajudassem a superar.
Além disso aprendi também bastante coisa nesse estágio, principalmente na parte de banco de dados por poder ver na prática muitos conceitos estudados na disciplina de Banco de Dados. E o mais legal disso tudo é que muito do que eu aprendi utilizando o Sybase, é valido para outros sistemas gerenciadores de banco de dados, inclusive na parte de comunicação de programas com a base. Tudo é muito parecido e eu comprovei isso na prática no meu atual estágio, onde usa-se o SQL Server da Microsoft.
Quanto às matérias do curso que foram mais importantes para o estágio posso destacar: MAC-110, MAC-122 e Estruturas de dados pela base forncecida, desenvolvimento da lógica de programação, e aprendizado da linguagem C; Os Laboratórios de programação pois foram matérias em que pude praticar bastante a programação, além de ter aprendido Perl e shell script que foram muito úteis no desenvolvimento do projeto; E é claro, Banco de Dados, pois era uma das ferramenta principais usadas no meu projeto.
Enfim, foi um estágio bastante interessante, no qual aprendi muitas coisas, pude aplicar os conhecimentos adquiridos no curso e também ganhar experiência desenvolvendo um projeto sério. Ou seja, aquilo que esperamos de um estágio.
{kind=link}