|
André Gustavo Andrade
oberon@linux.ime.usp.br
9. Dezembro 2002
Versão 0.1
O desenvolvimento formal (ou semi-formal) de agentes móveis requer um fundamento matemático que dê suporte à especificação e verificação tanto dos agentes individuais quanto do sistema como um todo. Vários dos problemas inerentes a agentes móveis estão ainda por ser completamente resolvidos. Pi-calculus é uma teoria para agentes móveis onde os agentes são dotado de identidade própria, com capacidade de replicação. Nele, a mobilidade dos agentes é denotada pela passagem de nomes de canais de comunicação por canais, permitindo que os canais sejam renomeados em tempo de execução. Em termos semânticos, a idéia de mobilidade de pi-calculus é refletida nas mudanças da topologia do sistema. Os agentes são elementos independentes que podem se movimentar ao longo da execução, mas a comunicação entre os processos é feita ponto-a-ponto, fazendo com que cada processo conheça todos os outros para poder se comunicar.
Pi-calculus tem sido aplicado na especificação e verificação de protocolos de comunicação em redes de sistemas móveis e, como framework, na definição semântica de linguagens de programação que contemplam o conceito de mobilidade. Apesar de ser um cálculo de referência para agentes móveis e para outros cálculos que tratam mobilidade, os estudos sobre pi-calculus se concentram em aspectos teóricos relacionados à expressividade e relações de equivalência computáveis. Desta forma, grande parte das ferramentas desenvolvidas para pi-calculus são protótipos que visam a certificação de aspectos teóricos desenvolvidos, sem vislumbrar o usuário final que deseja especificar os seus problemas reais.
O projeto em questão é interessante por vários motivos. Em primeiro lugar, é útil para o aprendizado de agentes móveis, que é uma área em ascenção, e em segundo lugar, por colocar em prática algumas técnicas vistas somente em teoria durante o curso.
Este ambiente amigável deve ser o mais configurável possível, para que a novas funcionalidades possam ser implementadas, de maneira que seja de grande utilidade para a comunidade científica.
Dessa maneira, pudemos aos poucos implementar novas funcionalidades, refatoramentos e reestruturações no código.
De um modo geral meu trabalho foi sempre dividido em duas etapas: A primeira, de leitura de artigos e livros, sendo que esta etapa quase sempre era seguida do aprendizado de novas tecnologias.
A segunda parte era implementação, onde todos os conhecimentos apreendidos deveriam ser convertidas em algo funcional e integrado ao resto do software ja desenvolvido.
Ocasionalmente, após cada uma das partes maiores serem implementadas, fazíamos uma reunião onde minha orientadora me instruia quanto ao que fazer em seguida e validava o que já havia sido implementado.
Minha orientadora manteve a linha a seguir quanto ao conhecimento teórico, me deixando mais livre para estudar e utilizar a tecnologia que eu quisesse para o desenvolvimento.
Isso estimulou-me a pesquisar mais, porque toda a responsabilidade da escolha da tecnologia seria minha, bem como o impacto da mesma no tempo e qualidade de implementação.
Nosso intuito de transformar a PiG em uma ferramenta de front-end para verificadores formais, é única até onde pude pesquisar.
Existem ferramentas com interfaces próprias, dentre as quais podemos citar:
O desenvolvimento da BNF de uma linguagem capaz de lidar com toda a versatilidade dos operadores do pi-calculus.
A interface gráfica para exibição e entrada de dados.
da BNF
Esta parte é importante pelo seguinte motivo: A BNF desenvolvida deve ser capaz de não só de lidar com pi-calculus, mas também de gerar uma árvore sintática facilmente tratável pela camada do simulador e pelos layers de software responsáveis por transformá-la em uma linguagem inteligível aos outros softwares.
Além disso, toda a implementação deve ser modularizada para que a implantação desses layers seja uma tarefa fácil.
A documentação também faz parte dos quesitos importantes para esta fase do projeto, visto que aqui reside a parte aberta deste software. Qualquer programador deve ser capaz de gerar o layer adequado a transformar a árvore sintática passada em qualquer outra linguagem que lhe interesse.
Ocasionalmente, até mesmo poderia se pensar no desenvolvimento de um framework para esses layers.
Gráfica
A interface gráfica se constitui de duas partes básicas:
A parte de RAD consiste em botões representando partes do código algébrico, de forma que a construção de um agente passa a ser feita de forma muito mais simples através de cliques e não de uma sintaxe decorada, e portanto, menos sujeito a erros.
São botões ou itens do menu acionados pelo usuário a fim de disparar uma certa ação sobre o agente selecionado.
:
Janelas pedindo informações de texto, necessárias em alguma parte algorítmica do programa.
ída de Dados:
Já a saída de dados pode ser feita através de texto ou gráfico.
Por isso mesmo, para coordenar tal diversidade, é necessária a criação de uma IDE, onde tudo isso possa ser feito na mesma tela e de forma amigável ao usuário.
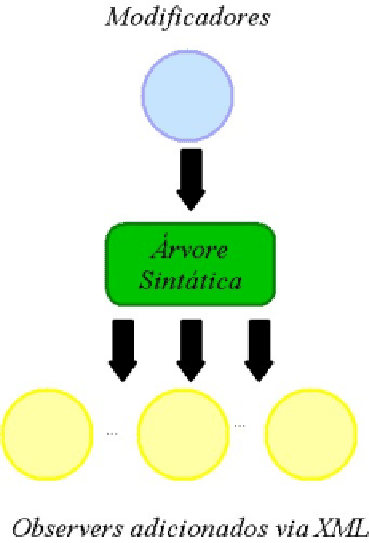
Assim, os componentes configuráveis se cadastram para receber notificações em caso de mudanças na árvore sintática, e também têm o poder de fazê-las. Veja a figura 1
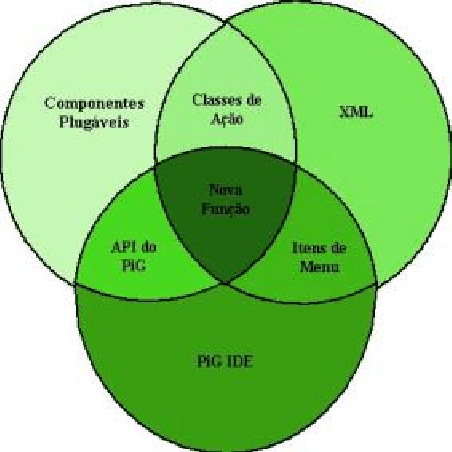
O sistema de componentes configuráveis descrito anteriormente, pode ser melhor compreendido olhando a figura 2
Até agora foram desenvolvidos dois componentes configuráveis para a PiG:
Assim, fez-se necessário o aprendizado de como reconhecer essa linguagem. Inicialmente trabalhamos em sistemas mais simples para o aprendizado.
Isto motivou-me a estudar os geradores automáticos de analisadores léxicos. Como não havíamos ainda decidido a linguagem na qual faríamos nossa ferramenta, estudei tanto as linguagens de geradores para C quanto para java. Como ambas pareciam-se muito, isto não foi um problema.
Por este motivo estudamos os analisadores sintáticos, e como montar alguns tipos.
Alias, Milner (O pai do Pi-Calculus) em seu livro introdutório ao mesmo, dedica praticamente metade do livro a fundamentos introdutórios necessários a intelecção de Pi-Calculus, dentre eles o CCS.
Com muita paciência de minha orientadora fui me sentindo seguro para assimilar a matéria, e passar a considerá-la uma base sólida para desenvolver o projeto.
Além da linguagem em si, era necessário definir também uma estrutura de árvore versátil o suficiente para que pudessemos operar sobre ela em aplicações futuras as quais não sabiamos ainda o que seriam.
Um pouco mais que isso, era preciso tomar uma decisão sobre a topologia da árvore, se seria uma árvore qualquer ou se restringiríamos a árvore a uma árvore binária (o que foi feito).
Porém, após o desenvolvimento desta etapa, percebemos que C não seria uma linguagem adequada por não satisfazer alguns requisitos definidos recentemente: A ferramenta deveria ser portável, escalável e massivamente gráfica, e interfaces gráficas em C não costumam ser fáceis ou portáveis.
Felizmente, como já havia estudado os geradores automáticos também para java, portar a parte do sistema que já estava pronta foi fácil.
Posteriormente acabei percebendo que desenvolver através de um paradigma orientado a objetos foi uma das melhores decisões que tomamos no projeto, mas mais uma vez, houve um atraso.
Um grande problema encontrado aqui foi que nenhuma das duas definições descrevia totalmente o Pi-Calculus, mas já eram esforços nesse sentido.
A aplicação de padrões de projeto permitiu que eu resolvesse pequenos problemas de forma ordenada evitando muito tempo de depurações e correções.
Sem dúvida foi uma das mais úteis pesquisas que eu empreendi. Não só no projeto da PiG, que foi bastante facilitado por estes, mas na minha vida como programador e desenvolvedor de software.
O protótipo era um simples interpretador, que fornecia a árvore sintática de uma sentença que o usuário entrasse expressa em nossa linguagem. A representação gráfica estava apenas no projeto.
Aos poucos fomos tentando incorporá-la no projeto, mas concluímos que talvez nosso tempo não fosse suficiente para fazê-lo. Assim, alguma medida de emergência deveria ser tomada.
Ou arriscaríamos o tempo desenvolvendo nossa interface gráfica, ou arriscaríamos o tempo no aprendizado de um framework (que como sabemos é realmente arriscado porque não se pode prever quanto tempo isso pode levar e se será bem sucedido) para depois podermos ganhar tempo quando um nível confortável de familiaridade fosse atingido.
Uma decisão de projeto deveria ser tomada. Optei então por usar um framework, e sem nenhuma dúvida foi este o momento mais delicado de todo o desenvolvimento.
Infelizmente para meu desespero, a documentação era escassa (constituindo-se de um javadoc de uma versão anterior à disponibilizada e o source code da versão atual). Mas ainda assim era melhor do que muitas ferramentas.
Mas a dificuldade foi um pouco superior à estimada.
Mas para descobrir detalhes como esses, era sempre necessário recorrer ao source code do framework. Foi um período de esforço contínuo.
Nesse tempo, me convenci de que a depuração persistente e o log constante constituem importantes ferramentas para ajudar o programador.
Essa pesquisa gerou um paper submetido para o PLoPIME2002 promovido pelo professor Fábio Kon.
O problema era o número de classes do sistema. Naquela época eu ainda não conhecia tecnologias como AspectJ. Do contrário, teria aliado as duas tecnologias com grandes ganhos. Além disso, programação voltada a aspectos é um assunto bem recente no qual vale a pena investir.
Pretendo introduzir essa tecnologia nas versões futuras da PiG.
Ao mesmo tempo, eu estava pensando em remodelar a arquitetura do sistema, de maneira a introduzir componentes plugáveis e configuráveis na PiG.
Assim, a produção de um pequeno módulo como este era extremamente útil, porque além de me permitir depurar as Pi-Nets, permitiria-me utilizá-lo como cobaia para ser o primeiro componente plugável da PiG. Mas para isso era necessário mais estudo.
Para resolver problemas como esse, a tecnologia de XML seria perfeita. Infelizmente, demandaria estudo tanto da estrutura de XML como de analisadores léxicos para a mesma em linguagem java.
Felizmente, o JDK1.4.1 já trazia um parser interno, na própria API disponibilizada pela SUN. E a documentação e tutoriais da SUN são impecáveis. Sorte minha.
A partir deste momento, os desenvolvedores teriam de ter conhecimento apenas de uma pequena API disponibilizada por nossa ferramenta para montar seus componentes, bastanto depois editar o XML para acoplá-los à PiG.
Gastamos mais um tempo definindo o que seria essa API de interface, e desacoplando as Pi-Nets para torná-las também um componente plugável juntamente com o verificador de árvore sintática.
Queríamos algo mais didático e intuitivo. Foi assim que nasceu as ObanaNets. Elas tem por objetivo mostrar de maneira clara como são as expressões entradas na forma de Pi-Calculus, sendo uma nova representação.
Este é o ponto onde estamos no momento. Ainda está em meus planos desenvolver um método de edição das ObanaNets, e possívelmente um pequeno simulador de comunicações monitorado, ou integrar esta ferramenta com algum simulador ou verificador formal já existente, consolidando nossa idéia original de que o PiG seja um front-end para os verificadores formais existentes e fechando assim o ciclo de pesquisas desenvolvido por mim durante a graduação.
Algumas atividades não foram listadas devido à sua repetitividade, como por exemplo testes, depuração e refatoramento do código.
Mesmo assim, houve um gasto considerável de tempo no aprendizado de técnicas de refatoramento.
Sempre uma atividade, qualquer que seja ela parece levar o dobro do tempo previsto para fazê-la, qualquer que seja este tempo. A incapacidade de cumprir os prazos adequadamente gerou uma certa angústia.
Mas vamos às dificuldades:
O vício por testar, a estruturação do projeto, a avaliação de riscos, todos foram conceitos utilizados para o desenvolvimento do PiG.
Assim, todos os conceitos que se aplicam a uma linguagem aplicam-se aqui também. Basta dizer que, PiG utiliza-se de um analisador léxico, e um analisador sintático, e que seu núcleo é uma árvore sintática.
Esta é uma matéria que além de revermos estes conceitos, aprendemos muitos aspectos físicos curiosos, e temos vivências práticas interessantes (afinal estar a 5 metros de algo que pode te matar em 10 segundos, azul brilhante, faz vc repensar a vida...).
Além disso, o conselho de refatoramentos agressivos foram muito úteis. Eu acredito que estes refatoramentos foram justamente o que permitiram que o projeto evoluísse sem que eu tivesse de jogá-lo no lixo algumas vezes durante o caminho.
Também foi uma disciplina importante no sentido de alertar no custo em tempo (imprevisível) de se implementar ou usar um framework. Depois de passar por esta experiência na pele, eu posso dizer que o tempo pode não ser imprevisível (pode ser estimado pelo tamanho do código de framework), mas ele é bem grande.
Essa interação permitiu que nós soubessemos sempre com o que cada um dos membros do nosso grupo de pesquisa estava trabalhando, e quando necessitávamos de alguma coisa que alguém já havia estudado, sabíamos a quem perguntar.
A intersecção entre nossas pesquisas nem sempre era grande, de forma que poucas vezes pudemos tirar benefícios disto para o trabalho de pesquisa, mas a contribuição para o aprendizado de novas teorias, ou abordagens diferentes para alguma teoria que já conhecíamos foi grande e deve ser ressaltado.
Algumas vezes os membros do grupo apresentavam seminários, o que nos forçava a estudar não só nosso tema de pesquisa, mas também uma forma didática de transmiti-lo aos outros. Assim, para aqueles que como eu pretendam seguir uma carreira acadêmica, foi uma atividade importante.
Começando por engenharia de software, pois um software dessa magnitude precisa ser bem documentado e definido, podendo ser usado portanto para refinar os conhecimentos que temos de especificação.
Também serão utilizados os conceitos de análise léxica e sintática em partes vista em autômatos e conceitos de linguagem durante a interpretação e montagem da árvore sintática dos processos.
Assim, este projeto me permitiu aprender a desenvolver com fluidez analisadores léxicos e sintáticos, que tem grande aplicação para a geração de linguagens de scripts, etc.
Uma vez que processos muito parecidos ocorrem dentro de compiladores e interpretadores (Sendo que o simulador não deixa de ser um interpretador) este projeto ajudará a compreender o funcionamento dos mesmos.
E ainda toda a teoria de pi-calculus que foge ao escopo da graduação, sendo uma área relativamente nova. Vários são os conceitos reunidos quando falamos em pi-calculus: Autômatos finitos, álgebras de processo, verificação formal dentre outros, complementando assim e constituindo um elo de ligação entre várias disciplinas aparentemente desconexas.
Com um pouco mais de estudo, poderei usar pi-calculus para a verificação formal de agentes móveis, o que me pode ser muito útil na verificação de protocolos que envolvam agentes móveis, uma área bastante em expansão nos últimos tempos.
Por fim e mais importante, programação gráfica e design de interface com usuário, que com toda certeza será usado em absolutamente todo o software desenvolvido ou projetado.
E eu colocaria alguns itens que não podem ser considerados como aprimoramento técnico, mas como trabalhos futuros a desenvolver em nossa ferramenta:
Não foi fácil, mas foi uma experiência gratificante. Primeiramente porque eu fiquei particularmente orgulhoso do meu trabalho e do meu desempenho. Em segundo lugar porque serviu para provar a mim mesmo que estou capacitado a trabalhar no mercado, a desenvolver softwares de grande porte, embora pretenda seguir a carreira acadêmica (e por isso a escolha de um tema para desenvolvimento ainda muito aberto a novas pesquisas).
Agora, olhando para tras, nem parece que foi tão difícil, e esse sentimento sempre motiva-nos a olhar pra frente e retomar um pouco da auto-estima perdida nesses quatro anos.
Saímos do colegial como os melhores da turma, entramos no vestibular mais difícil do país para logo a seguir sermos bombardeados com uma avalanche de notas ruins, trabalhos e todo o resto.
Não bastasse a diferença de ritmo e do nível de cobrança, ninguém se conhece. Em outras palavras, você está sozinho, desesperado e sem saber o que fazer. Não conhece os professores, a faculdade (que dirá a universidade...), muito menos a tutoria que existe e você só descobre isso no terceiro ano, quando não precisa mais.
O processo de se enturmar, superar as notas, os trabalhos, a falta de tempo, a correria, o desânimo, os: ``Isto é fácil, vocês já sabem'' tem o preço da auto-estima, que só começa a ser retomada novamente lá pelo quarto ano.
Quando você começa a fazer as fora de áreas você começa a perceber algo interessante: Muitas vezes você vai melhor do que as pessoas que fazem o curso do qual aquela disciplina faz parte. Até aí tudo bem. O estranho é que a nota nessas disciplinas muitas vezes acabam sendo a maior do histórico.
Em outras palavras: Será que eu consegui aprender mais em um semestre do que em quatro anos? Ou somos avaliados de maneira muito mais rigorosa do que todas as outras unidades?
Sinceramente tenho certeza que a segunda opção é verdadeira, só não estou certo da veracidade de primeira. Não sei até que ponto um aumento na exigência contribui para um aumento do aprendizado.
Diga-se de passagem, muitas matérias que eu cursei, me acostumei a decorar o conteúdo e colocá-lo de volta na prova porque não conseguia entender em tempo hábil para acompanhar o ritmo do curso, os professores pouco se importavam que isso estava acontecendo com a classe inteira e como resultado, dois dias depois da prova, nada mais restava. Foram conteúdos que eu só fui aprender quando estudava por conta própria em meu ritmo, num ritmo mais devagar.
Fica assim, uma crítica ao BCC.
Um fator extremamente importante foi que durante todo o curso, eu sempre estive envolvido em atividades extra faculdade. Isto permitiu que houvesse uma maior equilíbrio que muito me ajudou nos momentos difíceis do curso, embora muitas atividades (que pretendo retomar) tenham sido sacrificadas.
Outro comentário com relação ao curso que eu não poderia deixar de fazer: Aquela infeliz afirmação de que é necessário estudar duas horas por dia. Pode até ser realmente necessário. O questionamento é se isso é factível (aliás, um questionamento que deveria ser mais frequente entre o corpo docente), pois cursando 7 disciplinas, cada uma delas com 1 lista a cada duas semanas mais ou menos valendo nota, mais as provas (porque tínhamos uma a quase toda semana), mais os eps (que levam tempo para serem feitos), mais o tempo de condução, mais necessidades básicas (sono, comida...) é fácil fazer as contas e perceber a impossibilidade de se fazer isso.
Se a exigência é estudar duas horas por dia, ótimo. Propciem condições para que isso aconteça. Marquem semanas de provas, criem não eps, mas projetos que envolvam uma ou mais disciplinas, flexibilizem as listas de exercício, apresentações, seminários. É mais fácil jogar a culpa em alguém com afirmações generalistas do que mudar a estrutura do curso.
Voltando ao trabalho final, agora restringindo especificamente ao meu, foi a primeira vez que fui obrigado (e com isso tomando gosto por) a entrar em contato com um ambiente de pesquisa.
Muitas coisas não estão ainda definidas, você precisa criar coisas novas, discutir com pessoas que sabem mais que você, conversar bastante e ler mais ainda!
Enfim, preferi listar as características ruins do curso e que podem ser mudadas a listas as positivas, porque são incontáveis. Quando eu entrei no BCC eu achava que sabia programar. Hoje eu sei programar, mas não é o mais importante. Eu aprendi maturidade, responsabilidade, senso de dever, e acima de tudo: Pensar por conta própria.
Isto eu devo (e será uma dívida eterna) a todos aqueles nesse instituto com quem tive oportunidade de me relacionar. A essas pessoas, meu muito obrigado.
Como agradecimentos são muito pessoais, resolvi utilizar-me da minha forma usual de escrever, não me importanto com a estilística acadêmica, e dando-me algumas liberdades de expressão.
This document was generated using the LaTeX2HTML translator Version 99.2beta6 (1.42)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html article.tex -split 0
The translation was initiated by Andre Gustavo Andrade on 2002-12-09
![\includegraphics[scale=0.5]{tela1.eps}](img3.png)
![\includegraphics[scale=0.5]{tela2.eps}](img4.png)