Como os ruídos são particularmente críticos quando se possui pequenas amostras, então tentaremos encontrar classificadores para as características que sejam pouco sensíveis a estes ruídos. Partindo dessa idéia foi desenvolvido os chamados Strong Features Sets. Basicamente, para cada ponto do conjunto de treino é feito um espalhamento dos pontos segundo uma gaussiana e o classificador é desenvolvido sobre essa distribuição. Daí o algoritmo seleciona o conjunto de características que se preservam fortes em relação a espalhamento maiores. O erro provê uma medida da força de um par de características em função de um espalhamento.
2.2 Strong Feature Sets
Considere o conjunto de características( variáveis aleatórias ) X1 , X2 , X3 , ... , Xd as quais formam o vetor de características X = ( X1 , X2 , X3 , ... , Xd ). Um problema de classificação binária envolvendo X é determinado pela variável aleatória binária Y, que pode receber os valores 0 e 1. O classificador ψ é a função de X onde ψ(X) é um estimador de Y. O erro de ψ é definido pela esperança da diferença de Y e ψ(X)( ε[φ]=E[|Y-ψ(X)|] ), ou seja o erro é igual a probabilidade de uma classificação errônea( ε[φ] = P(ψ(X)≠Y) ).
O uso das características fortes (Strong Features) pode ser aplicado para o desenvolvimento de qualquer classificador, mas nesse estudo nos restringiremos a perceptrons ( classificadores lineares no espaço euclidiano ). Para um vetor de características X = ( X1 , X2 , X3 , ... , Xd, o perceptron é definido por ψ(X)=T( a0 + a1X1 + a2X2 + ... + adXd )
-
2.2.1 Desenvolvimento do Classificador
Dados uma distribuição conjunta de um grupo de características, o estimador linear optimal de Y é determinado por um vetor de pesos a. Seja Rx a matriz de correlação de X e E[XY] o vetor de correlação entre X e Y. Temos que se Rx for não singular, o vetor de pesos ótimo é dado por a=Rx-1E[XY]. Caso Rxfor singular, então Rx-1 é substituída pela pseudo-inversa de Rx. Assim para uma amostra de tamanho n temos
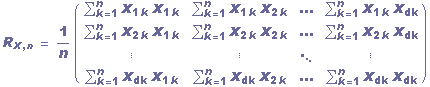
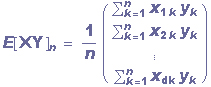
Daí aplicamos um espalhamento com RZ e obtemos um novo vetor de pesos w

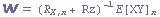
E por fim obtemos o perceptron classificador aplicando T(um threshold) sobre o estimador linear determinado por w.
2.2.2 Cálculo do Erro
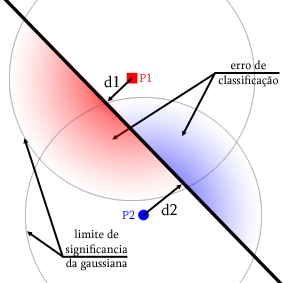
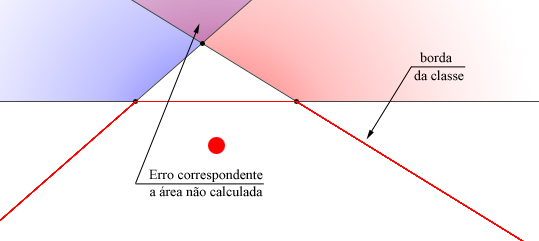
Se Z é parametrizado pela sua variância σ², então o perceptron resultante, ψσ é parametrizado por essa variância. Denotaremos de Z o espalhamento e de σ-perceptron o ψσ.Daí o erro εσ, para ψσ pode ser calculado analiticamente a partir do hiperplano definido. E sejam A0 e A1 referentes aos possíveis valores de X como pertencentes a classe 0 ou 1 respectivamente. Assim, para um espalhamento Z de variância σ², temos
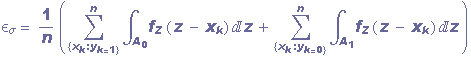
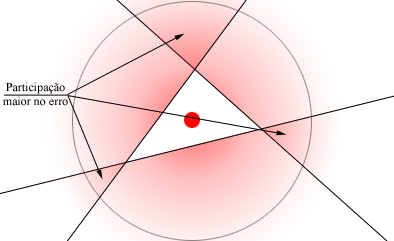
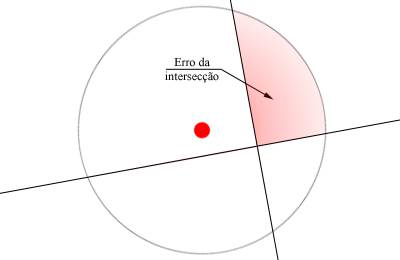
Ou seja, temos que cada ponto xk da amostra participa do erro total com sua extensão( resultante de RZ ) que está sendo erroneamente classificada.
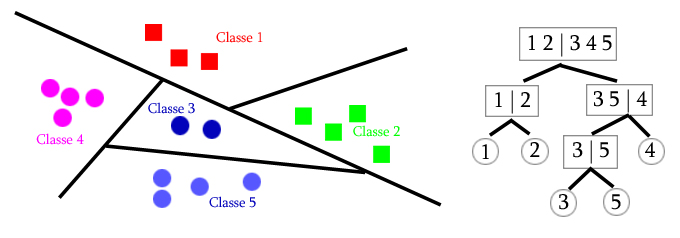
Com os classificadores lineares desenvolvidos, somos capazes de classificar um elemento dentre dois grupos distintos. No entanto, podemos ter mais do que duas possibilidades para um elemento. Nesses casos, podemos fazer as decisões em árvores, que consiste de uma série de classificações de conjuntos cada vez menores até que seja decidido por uma das classes.