Segmentação e Reconhecimento de Características Faciais
usando Homomorfismos entre Grafos
Aluno: David da Silva Pires
Projeto de Iniciação Científica
Supervisor: Roberto Marcondes Cesar Junior
http://www.vision.ime.usp.br/~creativision/
DCC - Departamento de Ciência da Computação
IME - Instituto de Matemática e Estatística
USP - Universidade de São Paulo
8 de dezembro de 2003
Resumo
Esta monografia apresenta o trabalho realizado durante a iniciação científica no intuito de melhorar um método já existente para segmentação e reconhecimento de regiões com características faciais usando homomorfismos entre grafos. Podemos entender regiões com características faciais como sendo sobrancelhas, íris, lábios e narinas. O método, conforme sua implementação anterior ao desenvolvimento deste trabalho, pode ser aplicado em imagens e até mesmo em seqüências de vídeo. Primeiramente, em uma imagem que contenha a foto do rosto de uma pessoa, a face é localizada. Este procedimento pode ser executado manualmente ou por meio da aplicação de uma técnica baseada na GWN (Gabor Wavelet Networks), a qual fornece uma localização aproximada das regiões de características faciais na imagem. A partir de então, a imagem é super-segmentada usando-se o algoritmo watershed. Esta imagem passa a ser representada por um grafo de atributos relacionais, o qual é rotulado convenientemente segundo um grafo modelo através de um homomorfismo. Esta rotulação nos fornece o reconhecimento das características faciais. A iniciação científica consistiu no estudo dos programas e scripts já existentes e em algumas tentativas de melhora dos mesmos tais como o desenvolvimento de uma melhor interface para indicação de regiões da face que deveriam ter o mesmo rótulo, pesquisa sobre a inclusão de dados 3D como atributos objeto do grafo, início de estudo para adaptação do modelo em quadros consecutivos de uma seqüência de vídeo, além de modularização do código desenvolvido. O professor Roberto Marcondes Cesar Junior foi supervisor e orientador deste trabalho.
|
Esta primeira parte descreve, de uma forma mais técnica, o projeto no qual a iniciação científica baseou-se, bem como os conceitos estudados e as tentativas de melhora realizadas. Algoritmos e estruturas de dados utilizados são explicados em detalhe e os resultados obtidos são apresentados.
A análise e o reconhecimento de faces têm recebido intensa e crescente atenção da comunidade de Visão Computacional, em parte devido às diversas aplicações, tais como interação homem-computador, codificação baseada em modelos, teleconferência, segurança e vigilância.
Uma tarefa importante que surge em diferentes problemas de reconhecimento de faces é a localização e segmentação de regiões de características faciais, tais como sobrancelhas, íris, lábios e narinas (9).
Para citar alguns exemplos de aplicação, a segmentação de tais características faciais é importante para o reconhecimento de faces baseado em características (1), aplicações médicas (6) e análise de expressões faciais (9).
Este documento apresenta um projeto de iniciação científica relacionado ao estudo e desenvolvimento de um método para segmentação e reconhecimento de regiões com características faciais usando homomorfismos entre grafos. O método pode ser aplicado tanto em imagens estáticas como em seqüências de vídeo.
Este documento está organizado como se segue. Os objetivos deste projeto serão discutidos no Capítulo 2, sendo as justificativas dadas na Seção 2.1, a qual leva em consideração a pesquisa bibliográfica discutida no Capítulo 8. O Capítulo 3 versa sobre a metodologia empregada. A Seção 3.1 apresenta uma abordagem baseada em grafos para a resolução do problema de segmentação de características faciais, incluindo o algoritmo de otimização e uma possível função critério. A aplicação destas ferramentas à segmentação de características faciais é descrita na Seção 3.2. No caso da presente aplicação, o método tira vantagem da saída da informação fornecida a priori sobre as posições dos marcos de interesse, limitando, assim, o espaço de busca e permitindo que a solução seja encontrada eficientemente. As ferramentas, outros materiais e métodos aplicados ao projeto são apresentados no Capítulo 5. Comentários sobre os avanços recentes e trabalhos futuros e a sugestão de critérios para avaliação dos resultados obtidos são mostrados no Capítulo 7.
O objetivo principal deste trabalho foi o estudo e desenvolvimento de algoritmos para segmentação e reconhecimento de características faciais aplicáveis tanto em imagens estáticas quanto em seqüências de vídeo. Em particular, interessou o aprimoramento da técnica desenvolvida em (3), com a grande vantagem de o orientador estar engajado no desenvolvimento da mesma. Nesse sentido, algumas tarefas em particular foram consideradas com maior atenção:
Naturalmente, este conjunto de objetivos permitiu que o aluno se familiarizasse efetivamente com a área, complementando sua formação.
O trabalho proposto, além de constituir um tema de pesquisa recente e desafiador, exigindo o estudo de várias disciplinas, também caracteriza-se por suas importantes aplicações na sociedade. De fato, existem diferentes aplicações possíveis que poderiam vir a utilizar futuramente os frutos do desenvolvimento deste projeto.
Como exemplos práticos de grande interesse da aplicação deste trabalho poderíamos citar:
Além das aplicações supracitadas, outros fatores evidenciam a importância do projeto, permitindo inclusive uma eventual bem sucedida divulgação em veículos científicos, tais como:
Enfim, o ponto central deste método de reconhecimento de faces, projeto que já estava em andamento, faz uso, na prática, de toda uma teoria que vem sido amplamente estudada em torno de casamento entre grafos, além de intensificar a colaboração já existente entre o IME-USP e o TSI-ENST-Paris, a qual já vem sido desenvolvida a um certo tempo e que já deu frutos tais como uma dissertação de mestrado (2) e artigos (3).
Primeiramente, em uma imagem que contenha o rosto de uma pessoa, a face é localizada e nela são indicados os marcos de interesse. Esta indicação pode ser feita manualmente, com o auxílio de aplicativos gráficos, ou então pode-se optar por métodos automáticos já existentes, tais como o desenvolvido numa dissertação de mestrado do Instituto de Matemática e Estatística (4). Neste último caso, após a localização da face, poderia-se optar por fazer o rastreamento da mesma por meio da aplicação de uma técnica baseada na GWN (Gabor Wavelet Networks). Este procedimento têm-se mostrado robusto para mudanças homogêneas na iluminação, deformações afins da imagem da face, mudanças nas expressões faciais e outras características que geralmente são agravantes para este tipo de tarefa, tais como piscar de olhos e sorriso.
Independente da forma como os marcos de interesse são indicados, a localização destes é apenas aproximada das regiões de características faciais na imagem. Desta forma, leva-se em consideração apenas um determinado raio em torno dos pontos marcados, ação esta que tem dois objetivos:
Na seqüência, a imagem é super-segmentada usando-se o algoritmo watershed. Esta imagem passa a ser representada por meio de um grafo de atributos relacionais (GAR), o qual é rotulado convenientemente segundo um grafo modelo através de um homomorfismo. Tal rotulação nos fornece o reconhecimento das características faciais.
Assim, o processo de reconhecimento equivale a encontrar um casamento
conveniente entre ambos os grafos: ![]() , que representa a face a ser
reconhecida, e
, que representa a face a ser
reconhecida, e ![]() , que representa a face modelo.
, que representa a face modelo.
O grafo modelo deve conter vértices associados a cada característica facial de interesse, por exemplo, para cada sobrancelha, íris, narina, boca e pele do rosto. A abordagem proposta permite a inclusão de outras características faciais, tais como óculos, dentes e barba e a técnica introduzida pode ser aplicada tanto em imagens estáticas quanto em seqüências de vídeo.
Representações através de grafos são amplamente usadas para lidar com informação estrutural em diferentes domínios tais como redes, interpretação de imagens, reconhecimento de padrões, etc. Um importante problema a ser resolvido quando se faz uso de tais representações é o casamento entre grafos.
Com o objetivo de obter uma boa correspondência entre dois grafos, o conceito mais utilizado é o de isomorfismo entre grafos, no qual procura-se pelo melhor isomorfismo entre dois grafos ou subgrafos. No entanto, em certos casos, faz-se necessário que o problema seja expresso como um casamento inexato de grafos. Por exemplo, casamentos inexatos entre grafos aparecem como uma importante área de pesquisa no campo de reconhecimento de padrões no qual, por vezes, um grafo representa o modelo e o outro a imagem cujo reconhecimento deve ser realizado. Devido ao aspecto esquemático usual do modelo e da dificuldade para segmentar precisamente a imagem em entidades significativas, não se pode esperar um isomorfismo entre ambos os grafos.
Muitos trabalhos sobre casamento inexato de grafos baseiam-se na
otimização de alguma função. Esta função geralmente mede a adequação
entre vértices e arestas e envolve ambas as similaridades entre
atributos de vértices e de arestas e também a estrutura do
grafo. Claramente, há muitos homomorfismos possíveis entre ![]() e
e
![]() , de modo que precisamos definir uma função critério a fim de
avaliar a qualidade de um dado homomorfismo e sua conveniência em
relação a cada aplicação específica. Em particular, podemos estar
interessados em encontrar um homomorfismo que minimize as diferenças
entre os atributos objeto dos vértices mapeados de
, de modo que precisamos definir uma função critério a fim de
avaliar a qualidade de um dado homomorfismo e sua conveniência em
relação a cada aplicação específica. Em particular, podemos estar
interessados em encontrar um homomorfismo que minimize as diferenças
entre os atributos objeto dos vértices mapeados de ![]() a
a ![]() e os
respectivos atributos relacionais associados às arestas casadas. O
problema é expresso como a otimização de uma função critério que nós
definimos de acordo com informações específicas sobre a face.
e os
respectivos atributos relacionais associados às arestas casadas. O
problema é expresso como a otimização de uma função critério que nós
definimos de acordo com informações específicas sobre a face.
Esta subseção trata das técnicas utilizadas durante a busca de um homomorfismo, dentre os vários existentes, entre os dois grafos definidos conforme explicação acima.
Segue uma descrição das notações e definições utilizadas, uma explicação sobre as possíveis funções critério que podem ser usadas e uma visão geral sobre o algoritmo de otimização.
Neste trabalho, ![]() é a representação de um grafo direcionado
é a representação de um grafo direcionado
![]() , onde
, onde ![]() é o conjunto dos vértices e
é o conjunto dos vértices e
![]() é o
conjunto de arestas de
é o
conjunto de arestas de ![]() . Dois vértices
. Dois vértices ![]() e
e ![]() de
de ![]() são ditos
adjacentes se
são ditos
adjacentes se ![]() . Se cada vértice de
. Se cada vértice de ![]() é adjacente a
todos os outros, então diz-se que
é adjacente a
todos os outros, então diz-se que ![]() é um grafo completo.
é um grafo completo.
Definimos um grafo de atributos relacionais (GAR) como sendo
![]() , onde
, onde
![]() determina um
vetor de atributos para cada vértice de N. Similarmente,
determina um
vetor de atributos para cada vértice de N. Similarmente,
![]() determina um vetor de atributos para cada aresta
de
determina um vetor de atributos para cada aresta
de ![]() . GARs têm sido extensivamente utilizados em Visão Computacional
e Inteligência Artificial em problemas de reconhecimento baseado em
modelos e análise estrutural de cenas. Em tais abordagens, a cena é
composta por um número de objetos dispostos de acordo com uma
determinada estrutura. Usualmente, cada objeto é representado por um
vértice do GAR, sendo caracterizado por um conjunto de características
organizadas pelo vetor de atributos de vértices, enquanto que as
arestas do GAR representam a relação entre cada par de objetos. Neste
contexto, os atributos de vértices e arestas
. GARs têm sido extensivamente utilizados em Visão Computacional
e Inteligência Artificial em problemas de reconhecimento baseado em
modelos e análise estrutural de cenas. Em tais abordagens, a cena é
composta por um número de objetos dispostos de acordo com uma
determinada estrutura. Usualmente, cada objeto é representado por um
vértice do GAR, sendo caracterizado por um conjunto de características
organizadas pelo vetor de atributos de vértices, enquanto que as
arestas do GAR representam a relação entre cada par de objetos. Neste
contexto, os atributos de vértices e arestas ![]() e
e ![]() são
chamados atributos objeto e atributos relacionais, respectivamente.
são
chamados atributos objeto e atributos relacionais, respectivamente.
Na abordagem presente, nós precisamos de dois GARs:
![]() e
e
![]() , os quais serão,
daqui em diante, referenciados como grafo de entrada (ou seja,
derivado a partir da imagem) e grafo modelo.
, os quais serão,
daqui em diante, referenciados como grafo de entrada (ou seja,
derivado a partir da imagem) e grafo modelo. ![]() denota o número
de vértices em
denota o número
de vértices em ![]() , enquanto
, enquanto ![]() designa o número de arestas em
designa o número de arestas em
![]() . No caso da segmentação de características faciais, geralmente
. No caso da segmentação de características faciais, geralmente
![]() é muito maior que
é muito maior que ![]() . Usamos um subescrito para denotar o
grafo correspondente, por exemplo,
. Usamos um subescrito para denotar o
grafo correspondente, por exemplo, ![]() denota um vértice de
denota um vértice de
![]() , enquanto
, enquanto
![]() designa uma aresta de
designa uma aresta de
![]() . Notações similares são usadas para
. Notações similares são usadas para ![]() .
.
Definimos o grafo de associação ![]() entre
entre ![]() e
e ![]() como sendo o
grafo completo
como sendo o
grafo completo
![]() , com
, com
![]() .
.
A definição acima de homomorfismo entre grafos assume que todos os
vértices em ![]() possam ser mapeados em
possam ser mapeados em ![]() . No presente caso da
aplicação de segmentação de imagens, na qual
. No presente caso da
aplicação de segmentação de imagens, na qual ![]() é geralmente
muito maior que
é geralmente
muito maior que ![]() , freqüentemente surge a situação em que muitos
vértices de
, freqüentemente surge a situação em que muitos
vértices de ![]() são mapeados em um único vértice de
são mapeados em um único vértice de ![]() . Tal
situação pode ser facilmente entendida, uma vez que, conforme
anteriormente mencionado,
. Tal
situação pode ser facilmente entendida, uma vez que, conforme
anteriormente mencionado, ![]() é obtido a partir de uma imagem
super-segmentada. Um homomorfismo conveniente entre
é obtido a partir de uma imagem
super-segmentada. Um homomorfismo conveniente entre ![]() e
e ![]() uniria coerentes subregiões na imagem de entrada super-segmentada,
mapeando os correspondentes vértices em
uniria coerentes subregiões na imagem de entrada super-segmentada,
mapeando os correspondentes vértices em ![]() a um mesmo vértice em
a um mesmo vértice em
![]() .
.
Uma solução entre ![]() e
e ![]() pode ser definida como um subgrafo
pode ser definida como um subgrafo
![]() do grafo de associação
do grafo de associação ![]() entre
entre ![]() e
e ![]() com
com
![]() ,
, ![]() tal que
tal que
![]() e
e
![]() o que nos garante que cada vértice do grafo da imagem possui
exatamente um rótulo (vértice do grafo modelo) e que
o que nos garante que cada vértice do grafo da imagem possui
exatamente um rótulo (vértice do grafo modelo) e que ![]() .
. ![]() é construído de modo a ser um subgrafo completo, isto é,
é construído de modo a ser um subgrafo completo, isto é,
![]() contém todas as arestas de
contém todas as arestas de ![]() que possuem extremidades em
que possuem extremidades em
![]() . Esta abordagem considera somente a estrutura dos grafos.
. Esta abordagem considera somente a estrutura dos grafos.
Claramente, há muitos homomorfismos possíveis entre ![]() e
e ![]() , de
modo que precisamos definir uma função critério a fim de avaliar a
qualidade de um dado homomorfismo e sua conveniência em relação a cada
aplicação específica. Este critério pode incluir, além dos aspectos
estruturais, informações sobre os atributos objeto. Em particular,
podemos estar interessados em encontrar um homomorfismo que minimize
as diferenças entre os atributos objeto dos vértices mapeados de
, de
modo que precisamos definir uma função critério a fim de avaliar a
qualidade de um dado homomorfismo e sua conveniência em relação a cada
aplicação específica. Este critério pode incluir, além dos aspectos
estruturais, informações sobre os atributos objeto. Em particular,
podemos estar interessados em encontrar um homomorfismo que minimize
as diferenças entre os atributos objeto dos vértices mapeados de ![]() a
a ![]() e os respectivos atributos relacionais associados às arestas
casadas. A próxima subseção apresenta duas funções critério que são
usadas para avaliar um dado homomorfismo, enquanto que a subseção
seguinte discute o algoritmo de otimização adotado.
e os respectivos atributos relacionais associados às arestas
casadas. A próxima subseção apresenta duas funções critério que são
usadas para avaliar um dado homomorfismo, enquanto que a subseção
seguinte discute o algoritmo de otimização adotado.
A avaliação da qualidade de uma solução representada por ![]() é
realizada através de uma função critério. Encontrar a melhor solução
de acordo com este critério significa minimizar esta função.
é
realizada através de uma função critério. Encontrar a melhor solução
de acordo com este critério significa minimizar esta função.
Uma função critério muito simples, introduzida em (3), pode
ser expressa como:
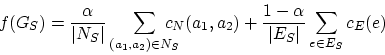
A função ![]() é uma média ponderada simples das medidas das qualidades
das associações entre vértices (primeiro somatório) e das associações
entre arestas (segundo somatório).
é uma média ponderada simples das medidas das qualidades
das associações entre vértices (primeiro somatório) e das associações
entre arestas (segundo somatório).
Tipicamente, ![]() é definido como sendo uma função decrescente da
similaridade entre os atributos de vértices. Se dois vértices
é definido como sendo uma função decrescente da
similaridade entre os atributos de vértices. Se dois vértices ![]() e
e
![]() possuem os mesmos atributos (alta similaridade), então o valor
de
possuem os mesmos atributos (alta similaridade), então o valor
de ![]() é muito baixo e a associação entre
é muito baixo e a associação entre ![]() e
e ![]() favorece na
minimização de
favorece na
minimização de ![]() . Por outro lado, associações entre vértices que
possuem diferentes valores de atributos são penalizadas. Similar
interpretação pode ser dada ao termo que depende das comparações
entre arestas.
. Por outro lado, associações entre vértices que
possuem diferentes valores de atributos são penalizadas. Similar
interpretação pode ser dada ao termo que depende das comparações
entre arestas.
Esta simples função é usada em nossos experimentos e o algoritmo
proposto na próxima seção pretende minimizar esta função. No entanto,
outras funções podem ser levadas em conta. Devemos notar que ![]() considera apenas a qualidade das associações atuais. Ela não leva em
conta possíveis semelhanças entre vértices ou arestas que não foram
casados. Todavia, soluções nas quais muitos nós não casados possuem
uma boa semelhança não deveriam ser favorecidas. Temos trabalhado em
outras funções critério, as quais serão usadas e comparadas em uma
atividade futura.
considera apenas a qualidade das associações atuais. Ela não leva em
conta possíveis semelhanças entre vértices ou arestas que não foram
casados. Todavia, soluções nas quais muitos nós não casados possuem
uma boa semelhança não deveriam ser favorecidas. Temos trabalhado em
outras funções critério, as quais serão usadas e comparadas em uma
atividade futura.
A fim de corrigir a falha da função critério ![]() definida
anteriormente, poderíamos definir uma função mais sofisticada, como
por exemplo:
definida
anteriormente, poderíamos definir uma função mais sofisticada, como
por exemplo:
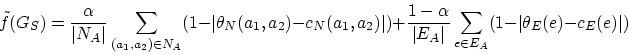
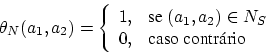

Nesta equação, se dois vértices possuem alta similaridade (baixo valor
de ![]() ) e realmente aparecem na solução, o valor do correspondente
termo no primeiro somatório é baixo e, portanto, tais soluções são
favorecidas. Por outro lado, se vértices que possuem grande semelhança
não aparecem na solução, então o valor do termo correspondente fica
próximo de 1 e tais soluções são penalizadas. Conclusões opostas podem
ser tiradas para vértices que possuam pouca similaridade. Raciocínio
análogo aplica-se às arestas. Sendo assim, esta função representa
melhor o fato de que uma boa solução deveria maximizar o número de
vértices ou arestas com alta similaridade casados e minimizar o número
de vértices e arestas com alta similaridade não casados.
) e realmente aparecem na solução, o valor do correspondente
termo no primeiro somatório é baixo e, portanto, tais soluções são
favorecidas. Por outro lado, se vértices que possuem grande semelhança
não aparecem na solução, então o valor do termo correspondente fica
próximo de 1 e tais soluções são penalizadas. Conclusões opostas podem
ser tiradas para vértices que possuam pouca similaridade. Raciocínio
análogo aplica-se às arestas. Sendo assim, esta função representa
melhor o fato de que uma boa solução deveria maximizar o número de
vértices ou arestas com alta similaridade casados e minimizar o número
de vértices e arestas com alta similaridade não casados.
Esta função ainda não foi testada até agora, porém o algoritmo de otimização proposto na próxima subseção pode ser facilmente modificado para se adaptar à mesma.
Com relação às funções que medem as similaridades entre vértices e arestas, podemos levar em conta características como nível de cinza médio, distância entre os centróides dos vértices ou a posição relativa entre eles.
O algoritmo procura uma solução através da criação de uma árvore com
cada vértice representando um par ![]() , onde
, onde ![]() é um vértice do
grafo de entrada e
é um vértice do
grafo de entrada e ![]() é um vértice do grafo modelo. Assim, a
definição desta árvore é análoga à definição do grafo de associação
é um vértice do grafo modelo. Assim, a
definição desta árvore é análoga à definição do grafo de associação
![]() , introduzido na Subseção 3.1.1.
, introduzido na Subseção 3.1.1.
A árvore de busca é inicializada com um vértice raiz ![]() que nada
representa. Esta raiz é expandida em
que nada
representa. Esta raiz é expandida em ![]() filhos:
filhos:
![]() . A função critério escolhida (vide Subseção
3.1.2) é calculada para cada filho. O próximo a ser
expandido é aquele de menor valor. Suponha que o par ordenado
. A função critério escolhida (vide Subseção
3.1.2) é calculada para cada filho. O próximo a ser
expandido é aquele de menor valor. Suponha que o par ordenado ![]() seja escolhido. Então, ele é analogamente expandido em
seja escolhido. Então, ele é analogamente expandido em ![]() filhos:
filhos:
![]() . A função critério é calculada
para cada filho recém-criado e toma-se a folha mais barata da árvore
como a próxima a ser expandida. Vale a pena notar que todas as folhas
são levadas em consideração, ou seja, vértices da árvore que não foram
expandidos anteriormente também são candidatos a serem expandidos. O
processo é repetido até que um vértice
. A função critério é calculada
para cada filho recém-criado e toma-se a folha mais barata da árvore
como a próxima a ser expandida. Vale a pena notar que todas as folhas
são levadas em consideração, ou seja, vértices da árvore que não foram
expandidos anteriormente também são candidatos a serem expandidos. O
processo é repetido até que um vértice ![]() é alcançado,
significando que cada um dos
é alcançado,
significando que cada um dos ![]() vértices de
vértices de ![]() foi mapeado
para algum vértice de
foi mapeado
para algum vértice de ![]() , definindo, assim, um homomorfismo entre
os dois grafos.
, definindo, assim, um homomorfismo entre
os dois grafos.
O algoritmo básico pode ser resumido da forma exibida no Algoritmo
1. Nele, é definida uma fila de prioridades e, quando o
procedimento priority_remove (p1) é chamado, é devolvido um
ponteiro para o vértice mais barato. O custo de cada vértice da árvore
é calculado na função explode baseado em uma das funções
critério discutidas na Subseção 3.1.2 e envolve a avaliação de
![]() e
e ![]() para os correspondentes vértices e
arestas.
para os correspondentes vértices e
arestas.
Temos limitado o tamanho máximo permitido para a fila de prioridades e, uma vez que este limite é alcançado, os vértices mais caros são eliminados da fila. Tal solução é similar ao algoritmo de procura beam, o qual economiza complexidade de tempo e espaço ao custo de não considerar muitos caminhos na árvore (e portanto possivelmente perdendo a melhor solução). Verificamos na prática que esta limitação permite que o algoritmo convirja muito rapidamente e que a qualidade da solução não depende criticamente do tamanho máximo permitido. De fato, verificamos que os principais problemas com nossa implementação atual baseiam-se nos atributos adotados, indicando assim que resultados melhores podem ser alcançados através do cálculo de outras características, tanto objeto quanto relacionais.
Finalmente, como também nos interessa a segmentação de características faciais em seqüências de vídeo, definimos uma função de custo de vértice, a qual explora a informação fornecida pelo algoritmo de rastreamento GWN e que restringe ainda mais os caminhos a serem seguidos na árvore de busca, acelerando a convergência conforme explicado na Subseção 3.1.2.
Esta seção introduz nosso método de segmentação de características faciais (SCF) baseado na procura por um homomorfismo conveniente entre dois GARs. Os pontos de referência faciais, localizados manualmente ou na fase de rastreamento com a GWN, são usados para definir uma região limitada, a qual é considerada pelo procedimento SCF. Desta forma, somente uma região circular, de raio fornecido a priori, em torno de cada ponto de referência, é levada em conta (vide Figura 3.1(b)).
Na abordagem atual, um GAR representa uma imagem segmentada, com cada
vértice associado a uma região conexa definida pela segmentação. As
arestas do GAR expressam um conjunto de relações espaciais entre cada
par de regiões da imagem segmentada. O método visa uma segmentação
precisa das características faciais de uma face de entrada baseando-se
em uma face modelo. Ambas as faces de entrada e modelo são
representadas por GARs, os quais serão, daqui em diante, referenciados
por ![]() e
e ![]() , respectivamente. O grafo modelo deve conter
vértices associados a cada característica facial de interesse, por
exemplo, para cada sobrancelha, íris, narina, boca e pele do rosto. A
abordagem proposta permite a inclusão de outras características
faciais, tais como óculos, dentes e barba. As próximas subseções
detalham cada aspecto importante da aplicação proposta.
, respectivamente. O grafo modelo deve conter
vértices associados a cada característica facial de interesse, por
exemplo, para cada sobrancelha, íris, narina, boca e pele do rosto. A
abordagem proposta permite a inclusão de outras características
faciais, tais como óculos, dentes e barba. As próximas subseções
detalham cada aspecto importante da aplicação proposta.
O passo inicial para segmentar as regiões de características faciais é localizar a face na imagem, o que pode ser feito tanto em fotografias quanto em seqüências de vídeo. Neste último caso, é necessário detectar a face em um quadro e rastreá-la nos quadros subseqüentes. Em nossa abordagem, estes passos são executados através de uma técnica proposta recentemente que representa uma face usando a Gabor Wavelet Networks (GWN) (4,13). Além disso, a GWN atua como um modelo rígido que fornece pontos de referência aproximados, os quais localizam-se perto das características faciais a serem segmentadas (por exemplo, olhos, nariz e boca). Estes pontos de referência são usados de duas formas diferentes, com o intuito de tornar nossa abordagem mais eficiente: (1) somente determinadas regiões em torno dos pontos de referência são consideradas; e (2) a informação dos pontos de referência é usada pelo algoritmo de otimização para diminuir o espaço de busca da solução, tal como explicado na Subseção 3.1.3. O leitor pode consultar (4) para detalhes completos sobre a abordagem pela GWN. A GWN permite um eficiente rastreamento da face em tempo real baseado na face por inteiro, sendo robusta para com deformações das características faciais tais como piscar de olhos e sorriso1.
A maneira mais fácil de se obter o grafo modelo ![]() é através da
segmentação manual da imagem de uma face seguida da representação pelo
correspondente grafo de atributos relacionais (GAR). A Figura
3.1(c) mostra a imagem de uma face que foi
manualmente segmentada para definir a face modelo e que foi usada em
experimentos preliminares. Uma abordagem mais robusta, que pertence à
pesquisa em desenvolvimento, é segmentar um conjunto de imagens de
faces e calcular os atributos do GAR a partir de diferentes
imagens. Esta abordagem permite a inclusão de vértices correspondendo
a características faciais específicas que podem não estar presentes em
algumas das imagens modelo, tais como dentes ou barba. Os atributos
dos vértices e das arestas associados são calculados somente a partir
das imagens em que eles estão efetivamente presentes. Cada vértice é
adjacente a todos os outros vértices e a si mesmo.
é através da
segmentação manual da imagem de uma face seguida da representação pelo
correspondente grafo de atributos relacionais (GAR). A Figura
3.1(c) mostra a imagem de uma face que foi
manualmente segmentada para definir a face modelo e que foi usada em
experimentos preliminares. Uma abordagem mais robusta, que pertence à
pesquisa em desenvolvimento, é segmentar um conjunto de imagens de
faces e calcular os atributos do GAR a partir de diferentes
imagens. Esta abordagem permite a inclusão de vértices correspondendo
a características faciais específicas que podem não estar presentes em
algumas das imagens modelo, tais como dentes ou barba. Os atributos
dos vértices e das arestas associados são calculados somente a partir
das imagens em que eles estão efetivamente presentes. Cada vértice é
adjacente a todos os outros vértices e a si mesmo.
É importante notar que, no modelo da Figure 3.1(c) algumas características faciais simples foram subdivididas, como por exemplo as sobrancelhas. Isto foi feito porque os atributos de vértices e arestas adotados, os quais serão introduzidos na Subseção 3.2.4, são calculados baseados nas médias das medidas sobre as regiões da imagem segmentada. Desta forma, atributos do modelo extraídos de grandes regiões tendem a ser menos representativos porque tais regiões freqüentemente apresentam uma maior variabilidade em relação aos atributos. Sendo assim, algumas características faciais têm sido subdivididas a fim de evitar tal problema em potencial. Além disso, o fato de que a pele não é uma característica facial bem-localizada (em contraste com as pupilas e as narinas) apresenta uma dificuldade adicional na introdução de relações estruturais entre a pele e outras características. Por exemplo, enquanto é possível definir relações estruturais tais como ``a pupila está acima das narinas'' ou ``a boca está abaixo do nariz'', seria mais difícil definir uma relação similar com relação à pele. Uma possível solução para este problema seria definir tipos alternativos de relações estruturais, tais como ``é rodeado por''. Ao invés disso, nós adotamos a abordagem de subdivisão da pele em subsegmentos (vide Figura 3.1(c)), o que nos permite usar os mesmos atributos relacionais entre todas as características faciais. Vale a pena enfatizar, entretanto, que a subdivisão das regiões do modelo implica em um aumento do número de vértices e arestas do grafo e, conseqüentemente, um aumento do número de possíveis soluções a serem consideradas pelo algoritmo de otimização (Subseção 3.1.3). Destarte, deve haver um acerto entre a qualidade dos atributos do modelo e o tempo de computação, o que deve ser cuidadosamente considerado no desenvolvimento do grafo modelo.
A imagem de entrada é segmentada através da aplicação do algoritmo watershed sobre o gradiente da imagem, resultando em uma imagem
super-segmentada (vide Figura 3.1(d)). É importante
que as arestas que definem as regiões faciais a serem segmentadas
estejam presentes na imagem super-segmentada. O grafo de entrada ![]() é obtido na seqüência a partir da imagem super-segmentada, com cada
vértice representando uma região conexa da imagem. Tal como no grafo
modelo, cada vértice de
é obtido na seqüência a partir da imagem super-segmentada, com cada
vértice representando uma região conexa da imagem. Tal como no grafo
modelo, cada vértice de ![]() é adjacente a todos os outros vértices
de
é adjacente a todos os outros vértices
de ![]() , além de ser adjacente a si mesmo.
, além de ser adjacente a si mesmo.
A definição de homomorfismo entre grafos discutida garante que todos
os vértices de ![]() são mapeados em
são mapeados em ![]() . Portanto, todas as regiões
faciais são classificadas e o problema de SCF reduz-se a encontrar um
homomorfismo conveniente entre os grafos
. Portanto, todas as regiões
faciais são classificadas e o problema de SCF reduz-se a encontrar um
homomorfismo conveniente entre os grafos ![]() e
e ![]() . O principal
problema em potencial com esta abordagem é que, mesmo que a face de
entrada apresente características não representadas no modelo, elas
serão classificadas. A Subseção 3.2.4 discute algumas
melhorias no método de modo a evitar este obstáculo.
. O principal
problema em potencial com esta abordagem é que, mesmo que a face de
entrada apresente características não representadas no modelo, elas
serão classificadas. A Subseção 3.2.4 discute algumas
melhorias no método de modo a evitar este obstáculo.
O conhecimento sobre faces é representado no GAR pelos atributos objeto e relacionais. Como foi explicado acima, os atributos objeto são calculados a partir das regiões conexas da imagem enquanto que os atributos relacionais são baseados na disposição espacial das mesmas.
Os atributos adotados para os experimentos apresentados neste documento são:
Há duas medidas de desigualdade, ![]() e
e ![]() , usadas pela primeira
função critério apresentada, sendo respectivamente ligadas aos
vértices e às arestas do grafo de associação.
, usadas pela primeira
função critério apresentada, sendo respectivamente ligadas aos
vértices e às arestas do grafo de associação. ![]() é uma medida de
desigualdade relacionada aos atributos objeto, enquanto
é uma medida de
desigualdade relacionada aos atributos objeto, enquanto ![]() é
relacionada aos atributos relacionais. Suas definições são dadas
abaixo.
é
relacionada aos atributos relacionais. Suas definições são dadas
abaixo.
Seja
![]() o grafo de associação entre os GARs
o grafo de associação entre os GARs ![]() e
e
![]() , como definido anteriormente. Tome
, como definido anteriormente. Tome ![]() indicando um
vértice de
indicando um
vértice de ![]() , com
, com ![]() e
e ![]() . A medida de
desigualdade
. A medida de
desigualdade
![]() é definida como:
é definida como:
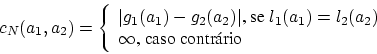
Seja ![]() uma aresta de
uma aresta de ![]() , com extremidades
, com extremidades
![]() ,
,
![]() e
e ![]() e
e
![]() ,
, ![]() e
e
![]() . A medida de desigualdade
. A medida de desigualdade ![]() é definida por:
é definida por:
Note que, ao utilizar ![]() como sendo a função a ser minimizada,
como sendo a função a ser minimizada, ![]() e
e ![]() devem ser calculados apenas para pares de vértices e arestas
realmente existentes em
devem ser calculados apenas para pares de vértices e arestas
realmente existentes em ![]() .
.
Alguns resultados obtidos com o algoritmo já desenvolvido são mostrados nas Figuras 3.1(e) e 3.1(f).
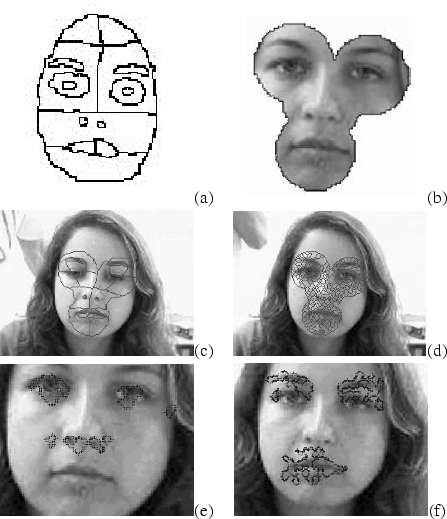 |
Nestes primeiros resultados, os parâmetros do modelo foram obtidos a partir do primeiro quadro (Figura 3.1(c)) de uma seqüência de vídeo obtida usando uma web-cam de baixo custo. Este modelo é então utilizado por todos os quadros da seqüência. Como pode ser visto, o resultado obtido apresenta uma estrutura coerente com relação ao modelo, embora seja necessária uma precisão maior.
Particularmente, algumas regiões próximas com nível de cinza parecido foram erroneamente unidas. Como por exemplo os olhos e as sobrancelhas e as regiões de pele escuras entre eles.
Todos os nossos resultados obtidos anteriormente têm sido similares na qualidade. Eles são promissores mas sugerem que os atributos são muito simples para resolver o problema e que outras características mais poderosas deveriam ser usadas. Por outro lado, o procedimento de procura converge muito rapidamente e os resultados foram obtidos usando uma fila de prioridades com um tamanho máximo de 20 nós, ou seja, somente 20 diferentes soluções possíveis são examinadas em paralelo, o que limita grandemente o espaço de busca.
Este trabalho já estava em andamento, de modo que a iniciação científica (1) ajudou na formação do aluno ao familiarizá-lo com o método e (2) aprimorou determinados aspectos do método já existente. Nesse sentido, a iniciação científica encaixou-se como sendo um dos esforços na colaboração entre o IME-USP e o TSI-ENST-Paris.
O desenvolvimento deste trabalho de iniciação científica baseou-se nos resultados divulgados em 2001 no VI Simpósio Ibero-Americano de Reconhecimento de Padrões sob o título First Results on Facial Feature Segmentation and Recognition using Graph Homomorphisms, de autoria de Roberto Marcondes Cesar Junior e Isabelle Bloch (3).
Outro trabalho correlato é o que foi desenvolvido pelo orientador Roberto Cesar em conjunto com E. Bengoetxea e Isabelle Bloch: Inexact Graph Matching using Stochastic Optimization Techniques for Facial, publicado em Proceedings of the International Conference on Pattern Recognition, em 2002 (11).
Além destes dois trabalhos descritos, também devem ser citados outros dois que darão seqüência ao que é apresentado neste documento. Trata-se (1) do mestrado da aluna Ana Beatriz Vicentim Graciano, que estenderá a técnica que aqui é apresentada, de imagens estáticas para seqüências de vídeo, e (2) do mestrado do próprio aluno da iniciação, David da Silva Pires, que dará continuidade a este trabalho em sua pós-graduação, a ser realizada com o mesmo orientador.
A bibliografia de base consta de livros recentes na área de Visão Computacional, tal como (3) por exemplo, além de artigos presentes em revistas especializadas. Livros clássicos disponíveis nas bibliotecas da USP também foram consultados (12,8,5,17). Também é importante salientar que a rede Internet foi intensamente explorada, constituindo uma significativa fonte de informações.
Com relação à parte computacional, os métodos já desenvolvidos estão escritos na linguagem C (compilador gcc, em ambiente Debian GNU/Linux, e na forma de scripts do MATLAB, software que oferece recursos para programação estruturada, diversas ferramentas matemáticas ligadas ao processamento de matrizes e uma ótima interface gráfica que facilita a visualização dos resultados. Ademais, os algoritmos definitivos deverão, possivelmente no trabalho de mestrado do mesmo aluno, ser implementados totalmente na linguagem C e integradas às bibliotecas em desenvolvimento junto ao Laboratório de Processamento de Imagens do IME-USP. Estuda-se uma integração dos resultados deste projeto com o programa de processamento de imagens da GNU, o GIMP.
Nossos programas, em geral, são distribuídos sob a licença GPL ( GNU Public License).
Temos como dados para teste um conjunto de fotos no formato JPEG (Joint Photographics Experts Group) além de seqüências de vídeo obtidas no laboratório com uma web-cam de baixo custo.
O equipamento exigido constitui o suporte computacional fornecido pelo IME-USP, bem como um conjunto de outros equipamentos que foram obtidos por meio de verbas do orientador.
Segue uma lista das atividades realizadas.
Durante a iniciação científica, iniciou-se um contato com Oscar Câmara, aluno de doutorado da professora Isabelle Bloch, na França.
Esta parceria visou a utilização de scripts em MATLAB, desenvolvidos pelo Oscar, para a realização de um pré-processamento, tanto das fotos de faces que serviriam de entrada para o algoritmo, quanto das imagens dos modelos criados. Este pré-processamento realiza o que se chama registro das imagens, que nada mais é que a aplicação de transformações afins que objetivam aproximar o modelo da face a ser reconhecida (ou vice-versa). Esta aproximação tende a melhorar a segmentação e o reconhecimento das regiões de características faciais.
Para facilitar a fase de registro, toma-se como entrada imagens que possuam apenas a região do foco de atenção. Atualmente, o registro realizado possui as seguintes características:
Uma abordagem para segmentação de características faciais baseada em homomorfismo entre grafos foi proposta. Neste contexto, definimos representações de uma imagem modelo e da imagem a ser reconhecida através de GARs, uma função critério e um algoritmo de otimização e os aplicamos para segmentar as características faciais tirando vantagem da informação de rastreamento fornecida pela técnica GWN.
Os resultados obtidos atualmente, embora apresentem uma estrutura coerente com relação ao modelo, necessitam de uma precisão maior. Particularmente, algumas regiões próximas com nível de cinza parecido são erroneamente unidas. Apesar de os resultados serem promissores, eles sugerem que os atributos são muito simples para resolver o problema e que outras características mais poderosas poderiam ser usadas.
O progresso do projeto pode ser avaliado levando-se em consideração os seguintes ítens:
Quando os programas existentes já estiverem produzindo resultados suficientemente satisfatórios, anseia-se pelo transporte de todo o código em MATLAB para a linguagem C, possivelmente realizando uma integração com o GIMP (GNU Image Manipulation Program)
Pretendemos passar a realizar o mapeamento entre os grafos utilizando aprendizado e simulação de redes Bayesianas, além da estimação de algoritmos de distribuição.
Finalmente, visamos aplicar este modelo de faces baseado em grafos a problemas de reconhecimento de faces e expressões faciais. Em particular, gostaríamos de analisar se mudanças temporárias nos atributos relacionais poderiam ser usadas para o reconhecimento de expressões faciais, pois tais trajetórias são importantes para a percepção de mudanças das mesmas.
Observa-se que a experiência anterior do orientador, bem como as ferramentas já desenvolvidas e disponíveis, como por exemplo o software na rede de computadores do grupo de visão do IME/USP, com o qual o aluno familiarizou-se, viabilizou o desenvolvimento deste trabalho como parte do programa de iniciação científica do mesmo.
O presente trabalho permitiu a formação de um aluno de iniciação científica na área de Visão Computacional e Processamento de Imagens, além de ter representado uma tentativa de melhora de um método interessante desenvolvido em um artigo do qual o orientador é um dos autores.
No progresso deste trabalho, visamos a melhora da robustez do método e a generalização do mesmo em diferentes formas, por exemplo, usando morfismos fuzzy (10), desenvolvendo outros atributos objeto e relacionais e tirando vantagem do homomorfismo encontrado no quadro anterior quando da procura do mesmo no quadro corrente de uma seqüência de vídeo.
O projeto baseia-se no artigo (3) escrito pelo orientador professor Roberto Marcondes Cesar Junior e pela professora Isabelle Bloch da Ecole Nationale Supérieure des Télécommunications da França. Para aprofundar o estudo dos algoritmos e tópicos abordados neste último, foram utilizadas algumas das referências bibliográficas citadas no mesmo, tais como (15,13).
Também serviram como objetos de referência artigos que tratam da aplicação da segmentação de características faciais no reconhecimento de faces (1), em aplicações médicas (6) e na análise de expressões faciais (9).
O tópico de detecção e segmentação de características faciais tem sido tratado em diversos artigos, do qual (9) é um bom exemplo para uma revisão atual no contexto de análise de expressões faciais. Alguns dos métodos mais populares incluem técnicas baseadas em casamento de padrões (9), projeções integrais (1), busca de pixels mais escuros (14), bordas (6), modelos flexíveis (7) e grafos (16). As principais vantagens e problemas das técnicas já propostas são discutidas em (9).
Além disso, foram estudadas as informações que constam de sítios afins, tal como http://cmm.ensmp.fr/~beucher/wtshed.html, o qual contém um tutorial sobre segmentação de imagens e morfologia matemática.
Esta segunda parte relaciona o projeto de iniciação científica com o curso de Bacharelado em Ciência da Computação do Instituto de Matemática e Estatística da Universidade de São Paulo.
Ao ingressar na USP, é comum sentir a sensação de que, de uma hora para outra, inúmeras portas se abrem para você. Este sentimento é percebido principalmente por alunos que ingressam a partir da rede pública de ensino.
A passagem pela barreira do vestibular lhe dá direito a freqüentar e realizar empréstimos de livros em diversas bibliotecas, ter aulas num centro de práticas esportiva completo, ter acesso a laboratórios equipados com computadores de última geração conectados 24 horas à Internet, além de estudar próximo a museus, teatros, anfiteatros e cinema, todos gratuitos.
No entanto, estes atrativos parecem ser pequenos perto da liberdade que têm-se em montar seu próprio currículo e especializar-se na área com a qual tiver maior afinidade. Já que qualquer curso da USP pode ser cursado por um aluno de qualquer unidade como disciplina extra-curricular, podemos concluir que a necessidade intelectual de qualquer aluno será bem satisfeita. Ao menos era assim que eu pensava no início do curso.
Acontece que, durante minha graduação no Bacharelado em Ciência da Computação do IME-USP, buscando uma formação mais ampla, sempre me matriculei em uma ou duas disciplinas a mais, além das recomendadas no currículo obrigatório. Isso inclui as disciplinas de Geometria Analítica, Elementos de Mineralogia e Petrologia, Ecologia e Lasers em Ciências da Vida.
Embora esta atitude possa ser considerada louvável por alguns, os resultados não foram nada animadores. Pelo contrário, o ``desastre'' foi tão grande, as notas tão baixas e tamanha foi a quantidade de disciplinas reprovadas que não recomendo esta estratégia a ninguém.
Hoje, concluo que meu mal desempenho acarretou nas minhas duas maiores frustrações durante a graduação: minha vergonha em mostrar meu histórico e o fato de, apesar de ter pleiteado um número considerável de vezes, nunca ter conseguido uma bolsa de estudos. Não importa o que se diz sobre as diferenças entre o conhecimento que a pessoa possui e sua capacidade de trabalho contra o que está impresso em um pedaço de papel: independentemente do caso de se estar sendo avaliado pelo setor de recursos humanos de uma empresa ou por um comitê avaliador para a concessão de bolsas de uma entidade de fomento à pesquisa, o histórico sempre possui importância significativa, quando não determinante, para o resultado da seleção.
Em suma, concluo que, para conseguir se formar no BCC em quatro anos e ainda assim possuir um histórico digno de ser exibido, deve-se dedicar totalmente ao curso e limitar-se ao currículo sugerido. Isso implica em abrir mão de diversas coisas em sua vida pessoal, estancar sua sede pela obtenção de conhecimentos em outras áreas ou então lutar por um BCC de 5 anos; mas estes já são assuntos polêmicos e é melhor deixar a discussão para uma outra ocasião. Fica apenas a sugestão para os ingressantes: batalhem por históricos impecáveis, sem reprovação e com boas notas; isso será muito exigido depois.
Deixemos as frustrações de lado e passemos aos desafios. Todos os desafios que encontrei durante minha iniciação científica renderam-me um conhecimento extra que certamente será muito bem aproveitado durante minha pós-graduação. Descrevo-os na seqüência.
Naqueles tempos (julho de 2001), eu não fazia idéia de como era realizada a divulgação científica. Simpósios, congressos, workshops, reuniões anuais e publicações em revistas especializadas, eu era completamente alienado a todos os eventos que possibilitam o intercâmbio de idéias entre os cientistas e que constituem a parte mais divertida do ambiente acadêmico: o relacionamento com as pessoas.
Amadureci muito nos últimos anos e acredito ter aprendido os objetivos da troca de informações e cooperação mútua visando o avanço científico. Certamente agora possuo maior facilidade para realizar pesquisas, uma vez que entrei em contato com os mais diversos motores de busca, repositórios de artigos, bibliotecas e sítios de interesse na área de Processamento de Imagens.
O primeiro item talvez advenha do fato de que, quando se entra no BCC, uma atitude que passa a ser comum é a troca de livros na cabeceira da cama em todo início de período letivo. É quando os Machados, Alencares e Vernes ``metamorfoseiam-se'' em Sedgewicks, Cormens e Knuths. Não que eu diga que a troca seja ruim. Apenas afirmo que a escassez de tempo para a leitura de textos literários acaba influenciando em momentos em que precisamos nos expressar por meio da escrita.
Já o segundo item refere-se ao aprendizado da ferramenta, o software a ser utilizado ao se escrever relatórios, pedidos de bolsa, artigos, transparências para seminários e até mesmo livros e apostilas para cursos. E é claro, quando se fala em qualidade tipográfica, logo pensa-se em LATEX. No início foi duro, eu sabia fazer apenas o básico e ainda assim torcendo o nariz para os comandos que não entendia. Agora, tomei gosto pela coisa, aprendo um pouco mais a cada vez que escrevo um documento e já até cheguei a dar dicas aos que, no início, me ajudaram.
São tantas provas, trabalhos, exercícios programa, projetos, listas de exercícios e apresentações que às vezes nos encontramos em meio a tudo sem saber o que fazer. A situação se agrava ainda mais quando os prazos são apertados ou as entregas são para o mesmo dia. São nestes momentos que começam a surgir pensamentos de desistência e uma incômoda conformidade com mais um ano de BCC passa a ser normal.
Neste capítulo são listadas as disciplinas, cursadas durante a graduação, que considero as mais relevantes no tocante à minha formação acadêmica. Ciente de que, apesar de haver um programa a ser obedecido em cada disciplina, os cursos acabam adquirindo conteúdo e formas de apresentação diferentes dependendo do professor que os oferecem, juntamente com os nomes das matérias também estou citando os professores que as ministraram no ano em que as cursei.
Sem dúvida, as duas disciplinas mais importantes para a minha iniciação científica foram MAC-417 (Visão Computacional e Processamento de Imagens) e MAC-447 (Análise e Reconhecimento de Formas: Teoria e Prática). Foram elas que me apresentaram a área em que pretendo continuar meus estudos. Ambas foram dadas pelo professor Roberto Marcondes Cesar Junior, cuja forma descontraída de dar aula e seu domínio sobre o assunto demonstram que ele é uma pessoa apaixonada por aquilo que faz. Foram estes motivos que cativaram meu interesse por fazer iniciação científica na área de Processamento de Imagens.
Também foram de grande importância, para uma maior facilidade na manipulação das estruturas de dados utilizadas e os algoritmos aplicados a elas, as disciplinas MAC-323 (Estruturas de Dados), que cursei com os professores Ernesto Goldberg Birgin e Yoshiharu Kohayakawa, e MAC-328 (Algoritmos em Grafos), dada pelo professor Arnaldo Mandel.
Certamente, não poderia deixar de citar a relevância das disciplinas básicas MAC-110 (Introdução à Computação) e MAC-122 (Princípios de Desenvolvimento de Algoritmos). Estes dois cursos, dados pelos professores Yoshiharu Kohayakawa e Paulo Feofiloff, respectivamente, em conjunto com MAC-211 (Laboratório de Programação I) e MAC-242 (Laboratório de Programação II), ambos dados pelo professor Marco Dimas Gubitoso, despertaram minha paixão pelo sistema operacional Debian GNU/Linux, fato que sem sombra de dúvida alavancou meu aprendizado sobre computação.
Como será dada continuidade ao trabalho aqui apresentado, seria injusto se eu não citasse disciplinas que cursei durante a graduação e que certamente influenciarão minha pesquisa daqui em diante na pós-graduação. Refiro-me a MAC-420 (Computação Gráfica) e MAC-425 (Introdução à Inteligência Artificial), dadas pelos professores Carlos Hitoshi Morimoto e Leliane Nunes de Barros, respectivamente.
Além das disciplinas supracitadas, gostaria também de mencionar outras duas que considero terem sido importantes para minha formação como cidadão e pessoa: MAC-424 (O Computador na Sociedade e na Empresa) e MAC-339 (Informação, Comunicação e a Sociedade do Conhecimento).
A primeira, ministrada pelo professor Valdemar Setzer, foge completamente do padrão de aula do instituto e trata de questões que são discutidas com fervor pelos alunos e que certamente, de tempos em tempos, voltam a cutucar a mente de cada um, instigando a pensar o mundo de um modo diferente. É difícil imaginar esta disciplina sendo dada por outra pessoa, tamanha a dedicação do professor Setzer em fazer com que suas idéias sejam entendidas.
Já a segunda disciplina, dada pelo professor Imre Simon, desperta o reconhecimento do valor existente na cooperação à distância e acaba fazendo com que os alunos passem a refletir sobre a influência de seus estudos para a sociedade e que tipo de benefícios poderiam ser gerados para a comunidade. Graças a esta matéria é que me tornei um defensor do movimento do software livre.
No início da iniciação, todo o Grupo de Visão Criativa ( Creativision) participava de reuniões semanais. Nelas, cada membro falava dos últimos passos dados nos respectivos projetos e vez ou outra havia um seminário para que todo o grupo pensasse como uma unidade e pudesse haver uma maior cooperação entre os membros. Eu gostava muito dessas reuniões e, de certa forma, eram elas que me impulsionavam a trabalhar, de modo a ter novos resultados que possibilitassem novas discussões na reunião seguinte.
No entanto, talvez devido à dificuldade de encontrar um horário em que todos do grupo pudessem comparecer, as reuniões deixaram de ocorrer. Desde então, minha dedicação à iniciação científica ficou diminuída e por diversas vezes era sobreposta por preocupações com as disciplinas do BCC. Agradeço aqui ao professor Roberto, por sempre ter compreendido minhas dificuldades e ajudar-me a superá-las.
Como não possuo computador em casa, todo meu trabalho foi feito no BIOINFO-I: Laboratório de Processamento de Imagens. Além de todo o aparato computacional de última geração instalado, também pude contar com a ajuda valiosíssima dos usuários do laboratório, pelos quais possuo grande estima.
A interação com a professora Isabelle Bloch e com seu aluno Oscar Câmara, colaboradores do projeto, deu-se apenas via correio eletrônico, quando da necessidade de trocar scripts e imagens ou fornecer informações sobre os novos programas.
O relacionamento com meu orientador não poderia ser melhor. Sempre mantivemos uma comunicação muito ativa, fosse pessoalmente, uma vez que sempre estávamos no instituto, ou via correio eletrônico. Mais que o relacionamento aluno-professor, prezo a valiosa amizade que desenvolvemos durante todos estes anos.
Durante minha graduação, algo que sempre me preocupou bastante foi como aplicar o conhecimento adquirido na academia em meio à comunidade.
Num país em que tantos passam fome, em que tantos têm de aprender a lidar com dificuldades financeiras desde cedo, durante a infância, e no qual a educação é precária e tão pouco valorizada, fica difícil encontrarmos uma aplicação da computação que possa amenizar tais problemas.
A única forma que encontrei para contornar esta situação foi através da participação como voluntário em projetos comunitários. Juntamente com o professor Roberto e Adriana Zavaglia e os alunos do IME Luiz Henrique Mariano de Araújo, Ana Beatriz Vicentim Graciano e Celina Maki Takemura, comecei a dar aulas de Processamento de Imagens nos Telecentros da Prefeitura de São Paulo. Nós criamos a Imaginux: Oficina de Processamento de Imagens no GNU/Linux, na qual ensinávamos a comunidade usuária dos telecentros a utilizar os programas GIMP, Xfig, xanim, mozilla e abiword para processar e lidar com imagens.
Logo no início, passei de voluntário a estagiário da Secretaria de Comunicação Social da Prefeitura do Município de São Paulo, passando a trabalhar na PRODAM, Companhia de Processamento de Dados do Município de São Paulo. Passei a integrar a Equipe Pedagógica, comandada por Thiago Guimarães. Nela, discutíamos como todo o parque computacional instalado nos telecentros poderia ser aproveitado de modo a haver um retorno para a sociedade. Neste contexto, ficou claro que o único tipo de aplicação que os conceitos estudados no BCC poderiam ter seria por meio da docência.
Outra situação em que observei aplicação da teoria na prática foi na administração de redes de computadores. Juntamente com os professores Roberto Marcondes e Roberto Hirata Jr. e com o aluno do mestrado Caetano Jimenez Carezzato, constituímos o grupo de administração da Rede Vision. Por meio das funções de um administrador, apliquei diversos conceitos aprendidos nas disciplinas de Redes e Sistemas Operacionais, além de aprender um pouco sobre ética e modos de tratamento para com os usuários. Agradeço muito aos três outros administradores, por tudo o que tenho aprendido com eles e pela paciência ao responderem a minhas dúvidas, por diversas vezes, básicas.
Para finalizar, observo que, do meu ponto de vista, há muito pouca proximidade entre as empresas e as universidades brasileiras, particularmente a USP. A pequena integração existente está longe de alcançar os padrões verificados em países onde este tipo de parceria dá certo. Penso que deva haver um esforço da comunidade acadêmica no sentido de incentivar cooperações entre empresas e universidades, a fim não só de melhorar a estrutura e os recursos destas, como também de aplicar, em um contexto real, todo o conhecimento que é gerado pelos pesquisadores.
Falar sobre os trabalhos incompletos na iniciação e que serão continuados na pós.
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -dir html -link 4 -split 0 -show_section_numbers -html_version 4.0 -no_math -local_icons -iso_language PT.BR -short_index -no_footnode -numbered_footnotes -discard -no_reuse -antialias_text -no_antialias -white -ldump -no_navigation -debug -verbosity 8 monografia
The translation was initiated by David da Silva Pires on 2003-12-16
![\begin{algorithm}
% latex2html id marker 125
[!hbtp]
\caption{Árvore de Busca} ...
...ém-nascidas na fila de prioridades}
\ENDWHILE
\end{algorithmic}\end{algorithm}](img115.png)