No início, o objetivo principal era montar um grande Banco de Dados com arquivos de fala em diversas línguas, de forma a expandir a análise estatística que já havia sido feita até entăo com um conjunto restrito de dados e em poucas línguas (a saber: Inglęs, Holandęs, Polonęs, Espanhol, Catalăo, Francęs, Italiano e Japonęs, em grande quantidade, além do Portuguęs Europeu e Portuguęs Brasileiro, com poucos dados coletados. Esses dados podem ser obtidos
aqui).
Aproveitando o grande o grande volume de dados disponíveis na Internet, partiu-se em busca de arquivos com sentenças ditas de forma clara, natural (o que excluía, por exemplo, pessoas cantando) e sem sons externos (ruídos, músicas de fundo, etc). Com estas restriçőes, os noticiários internacionais tornaram-se a maior fonte de dados dessa fase inicial do projeto.
No entanto, foram notadas diferenças consideráveis entre os espectrogramas dos arquivos disponíveis anteriormente (os quais haviam sido gravados em estúdio) e os dos arquivos dos noticiários, e o grupo de trabalho chegou ŕ conclusăo que essa diferença se devia ao fato dos dados disponíveis na Internet estarem, em sua maioria, em formatos comprimidos (provavelmente para um acesso mais rápido e menor espaço de armazenamento necessário), o que, conseqüntemente, "contaminava" os dados. Dessa forma, utilizaçăo desses arquivos para a expansăo da base de dados do projeto ficou impossibilitada.
Com esse revés, os objetivos iniciais do meu projeto de Iniciaçăo Cinetífica foram revistos e passei a lidar diretamente com o Piccolo. Para começar iniciei um refatoramento do programa -- desenvolvido inicialmente em Perl por Jesus Garcia --, de modo a torná-lo mais eficiente e claro. Ao mesmo tempo, desenvolvi uma Interface Gráfica
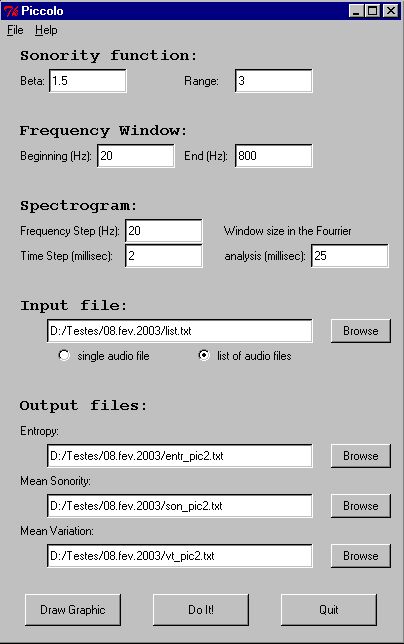
* (
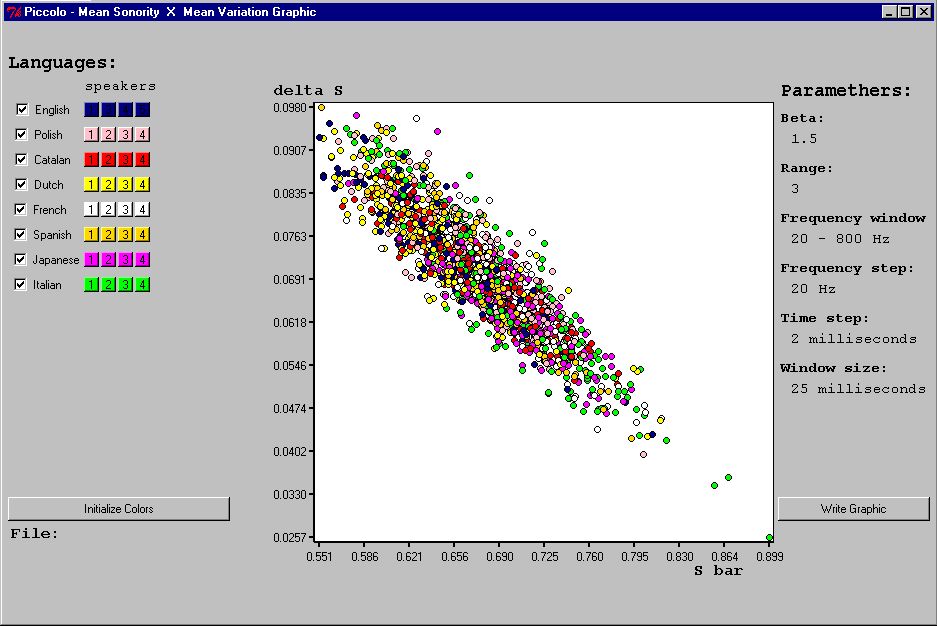
figura 1) para o programa, a fim de que usuários familiarizados com o projeto mas leigos em relaçăo ŕ linguagem Perl pudessem utilizar o programa sem grandes dificuldades. Também foi desenvolvido um novo módulo para a visualizaçăo de gráficos com os resultados obtidos pelo programa (
figura 2).
O passo seguinte foi unificar as versőes existentes para todos os tipos de dados e expandir seu uso para diferentes Sistemas Operacionais, pois antes havia tręs versőes, todas para Windows. A nova versăo do Piccolo foi também extensamente comentada para facilitar seu entendimento por pessoas de fora do projeto ou por futuros novos membros que queiram dar continuidade ao desenvolvimento do programa.
Atualmente o programa está sendo finalizado e sua saída (arquivos com as entropias relativas) sendo integrada ŕ tecnologia XML. Um manual de auxílio ao usuário também está sendo desenvolvido para que pessoas do mundo todo possam utilizar o programa e contribuir com dados para o projeto (veja uma versăo beta
aqui). Além disso, os dados acústicos e os programas necessários para rodar o Piccolo serăo reunidos em um CD-ROM ou poderăo ser baixados pela Internet. Uma versăo parcial deste CD-ROM já está
disponível aos interessados.
volta ao início
Outras atividades já realizadas
- Leitura dos artigos [1] e [2];
- Participaçăo na VI Escola Brasileira de Probabilidade (agosto/2002), tendo freqüentado o mini-curso "Markov Models and Hidden Markov Models in Genome Analysis", ministrado por Bernard Prum;
- Minicurso da Suzi.
volta ao início
O que falta ser feito
No próximo semestre pretendo finalizar o programa e seu Manual de ajuda, além de alterar a saída do mesmo para o formato XML.
volta ao início
Estrutura da Monografia
Seguindo o
roteiro para preparaçăo das monografias, pretendo dividir minha Monografia em duas partes:
volta ao início
Referęncias:
[1] Galves, A.; Garcia, J., Duarte, D., Galves, Ch. (2002) Sonority as a basis for rhythmic class discrimination, in Proceedings of the Speech Prosody 2002 conference (ISBN 2-9518233-0-4), 323-326, 2002. Pode ser obtido
aqui.
[2] Ramus, F.; Nespor, M.; Mehler, J., 1999. Correlates of linguistic rhythm in the speech signal. Cognition, 73, 265-292.
volta ao início
* Agradeço especialmente ao professor Gubi pela ajuda e atençăo nessa parte.
{kind=link}
{kind=link}