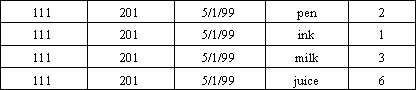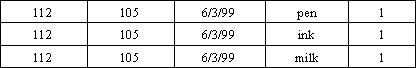MAC499
- Trabalho de Formatura Supervisionado
Implementação de Algoritmos de Data Mining no PostgreSQL
Aluno: Thiago Faria Marzano (marzano at
linux ponto ime ponto usp ponto br)
Orientador: João Eduardo Ferreira
OBS: Este texto está sobre condiçao de revisao, e será reenviado pelo aluno assim
que o seu orientador indicar alguma necessidade de revisao do mesmo.
1 -Introdução
A necessidade de análise de dados e
previsão de tendências no mundo hoje é muito
grande, e poucas ferramentas hoje em dia fazem essa análise.
Esse é o intuito deste desenvolvimento: capacitar uma ferramenta
de uso em larga escala a realizar essa análise. No
Capítulo 2 falarei sobre a teoria relacionada a Data Mining, No
Capítulo 3, o sistema será explicado, com ferramentas
utilizadas e a tecnologia aplicada no sistema. No quarto
capítulo falarei sobre a esperiência pessoal adquirida
nesse trabalho e as dificuldades que me tomaram mais tempo e no
último capítulo estão as referências
bibliográficas
2 - Data Mining
"Data Mining é o processo de
descoberta de novas e significantes correlações,
padrões e tendências, filtrando grandes quantidades de
dados guardados em repositórios, utilizando tecnologias de
reconhecimento de padrões bem como técnicas
matemáticas e estatísticas."
Data Mining esta relacionado com uma subarea da
estatística denominada Análise Exploratória de
Dados e também está relacionado com as
subáreas de Inteligência Artificial denominadas Knowledge
Discovery e Machine Learning. A diferença mais
importante está no fato de que Data Mining trabalha com um
volume imenso de dados e por esse motiva necessita de algoritmos
altamente escaláveis, ou seja, algoritmos em que o tempo
de execução cresca linearmente em
relação ao volume de dados.
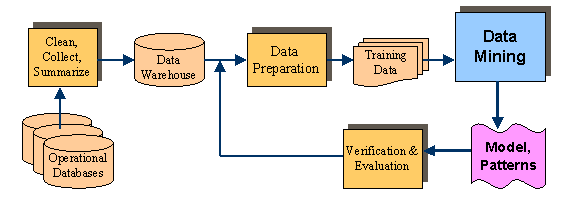
2.1- Knowledge Discovery Proxcess
KDD: Knowledge Discovery Proxcess, ou KDD Process
pode ser dividido a grosso modo em cinco partes:
- Data Selection: Neste passo identificamos o conjunto de
dados e atributos a serem utilizados.
- Data Cleaning: Removemos dados que possam interferir no
processo, transformamos os dados para unidades comuns, geramos novos
campos através da combinação de campos já
existentes e trazemos tudo isso para o esquema relacional que
será utilizado para o processo de Data Mining
- Denormalization (optional): Esta é uma parte
opcional do processo mas que é normalmente realizada onde muitas
tabelas sofrem uma denormalização para facilitar o
processo de mining
- Data Mining: Este é o passo onde entram as
tecnicas de Data Mining existentes que serão aplicadas em cima
dos valores gerados nos campos anteriores.
- Evaluation: Neste passo, formatamos os padrões
encontrados no passo de Data Mining e os apresentamos, de uma forma
inteligível, ao usuário final.
Todos esses passos, estão sintetizados na seguinte figura:
2.2 - Contando
ítens freqüentes:
Temos que considerar agora o problema de contar
os ítens mais
freqüentes
no mundo do Data Mining. Um ponto a se observar é o fato
de que estamos
lidando com uma gigantesca quantidade de dados o que nos leva ao fato
de necessitarmos de algoritmos escaláveis como já
citado anteriormente.
Vamos definir o conceito de Market Basket
que nada mais
é do
que uma coleção de ítens adquiridos de uma
única vez através de uma transação
(sendo
que uma transação aqui não é no mesmo
sentido que uma transação de bancos de dados e sim
mais no sentido de transação financeira, seja ela real,
ou virtual).
Contar os ítens mais freqüentes é
uma tarefa
desejada pois desse modo podemos descobrir
quais ítens são os mais vendidos e deseja-se saber
também quais ítens são frequentemente
adquiridos em conjunto.
Chamaremos de Conjunto de Ítens o
termo em inglês itemset
cujo significado
se torna imediato e manteremos em inglês o termo support
que é fração de transações
que contém todos os ítens daquele conjunto de
ítens. Também estamos interessados em Conjuntos
de Ítens que contenham apenas um ítem. Dizemos tambem que
um conjunto de ítens é freqüente quando
o support do mesmo é maior que um número
denominado minsup que é atribuído pelo
usuário.
O algoritmo para realizar a geração de
conjuntos
frequentes de ítens é baseado na propriedade
"a priori" que diz que cada sub-conjunto de um conjunto freqüente
de ítens deve também
ser um conjunto freqüente de ítens.
Algoritmo:
foreach item,
check if it is a frequent itemset
k = 1
repeat
foreach new frequent itemset Ik with kitens
generate all itemsets Ik+1 with k+1 item, Ik C Ik+1
Scan all transactions once and check if the generated k+1-itemsets are frequent
k = k + 1
until no new frequent itemsets are identified
Com esse algoritmo podemos então
contar eficientemente os
Conjuntos de Ítens de nosso banco
de dados já que pela hipótese "a priori"
descartamos a maior parte das
possibilidades.
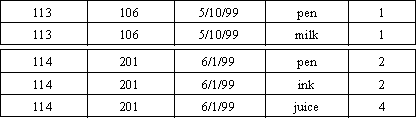
Da nossa tabela de exemplo, aplicando o algoritmo
extraímos como
exemplo os seguintes conjuntos
de ítens: {pen}, {ink}, {milk}, {pen,ink}, {pen,milk} e
{ink,milk}
2.3 Regras de Associação:
Uma regra de associação tem a seguinte forma:
Onde tanto LHS quanto RHS
são conjuntos de
ítens e a interpretação da
regra é simples: Se todos os ítens em LSH forem
adquiridos, então é provável que
os ítens de RHS também sejam adquiridos.
Exitem duas medidas importantes para regras de
associação:
- Support: O support
de um conjunto de ítens é a porcentagem de
transações que
contém todos esses ítens como já dito
anteriormente. O support para a regra LHS => RHS
é o support para o
conjunto LHS U RHS.
- Confidence: Considere apenas as
transações
que contém todos os ítens em LHS.
O confidence para a regra LHS => RHS
é a porcentagem das transações que
também contém todos os ítens de RHS.
Mais precisamente, o confidence da regra LHS => RHS
é sup(LHS U
RHS) / sup(LHS).
Definimos agora
minconf como
sendo o valor mínimo de confidence de uma regra e
minsup o valor mínimo de support de uma regra.
Podemos agora então gerar um
algoritmo que calcule todas as regras de associação que
batam com os critérios de minsup
e minconf mínimos definidos.
O Algoritmo é simples e é baseado no
algoritmo de calculo
de conjuntos de ítens freqüentes, aliás,
como um primeiro passo do algoritmo devemos gerar todos os conjuntos
freqüentes. Para gerar
uma regra de associação a partir de um conjunto de
ítens freqüentes X, dividimos
X em dois conjuntos de ítens freqüentes (sabemos que
são freqüentes devido a regra do
"a priori"). Podemos então calcular o confidence da
regra candidata através da
fórmula sup(X)/sup(LSH)
e comparar com minconf
para atestar a validade da regra de acordo com nossos critérios.
2.3.1
Regras de Associação e Hierarquias ISA:
Em muitos casos é imposta uma
Hierarquia ISA sobre o conjunto de ítens e na presença
de tal hierarquia, implicitamente uma transação
contém, para cada um dos seus ítens, todos
os outros ítens ancestrais da hierarquia. A hierarquia nos
permite detectar relacionamentos
entre ítens de diversos níveis da hierarquia.
Como um exemplo, o support do conjunto de
ítens {ink,juice}
é 50%, mas se substituirmos o íten juice pela
categoria mais geral beverage
teremos então o conjunto de ítens {ink,beverage}
cujo support é incrementado
para 75%.
2.4 Algoritmos de Data Mining
1. Decision Trees - Este algoritmo é
baseado em classificação. O algoritmo constrói uma
árvore de decisão que irá prever o valor de
colunas em uma tabela de fatos, com base em outras colunas na tabela de
fatos.
Árvores de decisão são uma forma simples de
representação de conhecimento e elas classificam exemplos
para um número finito de classes, os nós são
rotulados com os nomes de atributo, as extremidades são
rotuladas com possíveis valores para este atributo e o
rótulos das folhas com classes diferentes. Objetos são
classificados seguindo um caminho abaixo a árvore, levando as
extremidades, correspondendo aos valores dos atributos em um objeto.
2. Clustering (BIRCH) - Este algoritmo
agrupa registros em clusters que exibem algumas características
similares previsíveis. Freqüentemente, estas
características podem estar escondidas ou não serem
intuitivas.
A técnica de clustering consiste em agrupar os dados de acordo
com valores em comum. Os dados são colocados em um
gráfico baseados em valores de algum de seus atributos em uma
das coordenadas em observação (x, y ou z). Tipicamente,
quando esses valores representam um conjunto arbitrário de
descrições (ex.: nomes, doenças, números de
identificação, tipos de conta) aparecerão
concentrações de dados com valores em comum.
O Algoritmo BIRCH (Balanced Iterative Reducing and
Clustering using Hierarchies) foi escolhido pois ele trata os dados em
computadores com memoria limitada.
3 - Sistema Desenvolvido
O sistema será desenvolvido seguindo a
estrutura abaixo mostrada:
3.1 - PostgreSQL
O PostgreSQL é um sofisticado sistema de
gerenciamento de banco de dados relacional e orientado a objetos,
suportando quase todas as contruções SQL, incluindo
subseleções, transações, tipos definidos
pelo usuário e funções. Ele é o mais
avançado banco de dados de código livre
disponível. Atualmente está disponível seu
código fonte, além de binários
pré-compilados em diversas plataformas, o que justifica a sua
escolha como sistema de gerenciamento. Outro motivo é pelo fato
de que o PostgreSQL tem uma implementação muito vasta da
Linguagem SQL, o que facilita o desenvolvimento.
3.2 - ECPG - Embedded SQL in C
Um programa com Embedded SQL consiste em
código escrito em uma linguagem de programação, no
caso a linguagem C, mixado com comandos SQL em algumas
seções do código. Para construir o programa, o
código-fonte deve passar pelo pré-processador de Embedded
SQL, que converte o programa em um programa comum na linguagem C, e
então o programa deve ser compilado em um compilador habitual.
Embedded SQL tem vantagens em relação
a outros metodos de gerencia de comandos SQL em código C.
Primeiro, ele toma o cuidado da parte mais chata de passar a
informação de e para variáveis no programa em C.
Segundo, o codigo SQL é verificado em tempo de
compilação para verificação
sintática. Terceiro, o embedded SQL em C é especificado
no padrão SQL Standards e suporta muitos gerenciadores de banco
de dados que usam SQL, e como o PostgreSQL foi desenhado para seguir o
padrão quanto mais possivel, é facil portar programas
usando Embedded SQL feitos em outros sistemas para o PostgreSQL.
Esses foram os motivos da escolha do Embedded SQL
3.3 - libpq - C Library
libpq é a Interface de
Programação para Aplicações em C que usam o
PostgreSQL. libpq é um conjunto de bibliotecas de
funções que permitem ao cliente que passe queries ao
servidor PostgreSQL e receber os resultados dessas queries. libpq
é também o núcleo de funcionamento de outras
interfaces de programação do PostgreSQL, incluindo
libpq++ (C++), libpgtcl (Tcl), Perl, e ECPG.
3.4 Estrutura
A estrutura final do meu sistema fica então
da seguinte forma:
- Usuário inclui tabelas no PostgreSQL
- Usuário define quais tabelas serão usadas para
a sua análise
- A aplicação cliente pede ao PostgreSQL as
infiormações dessas tabelas, ja tratando via queries os
dados importantes
- A aplicação cliente executa a análise
usando algum dos algoritmos escolhidos pelo usuário
- A aplicação cliente transforma a analise
conseguida para ser visivel ao usuário e retorna a esse
usuário
4 - Experiência Pessoal
4.1 - Desafios e Problemas
Como todo sistema de computação,
varios desafios foram emcontrados, que geraram muitos problemas. Os
desafios proncipais foram:
- Apesar do PostgreSQL ser uma ferramenta livre, é
difícil achar documentação sobre a parte interna
do sistema sem que você tenha que olhar o código interno
dele, o que é uma tarefa muito árdua devido ao seu
tamanho. Isso me gerou o problema de demorar muito para entender o
funcionamento interno do PostgreSQL
- Não dá para confiar em toda a
documentação existente sobre Data Mining, pois muita
coisa não explica nada sobre o processo e os algoritmos e isso
me gerou uma dificuldade enorme pois varias vezes tive que voltar a
procurar documentação boa pois a que eu tinha não
supria minhas necessidades
- Tive muitos projetos e provas relacionados a outras
matérias no meu curso, e isso acabou atrasando bastante o
desenvolvimento do sistema pois tinha que dividir demais o meu tempo e
muitas vezes acabava escolhendo outros projetos para me dedicar mais
pois eles tinham um prazo menor
- No meio do segundo semestre tive um desanimo muito grande
com relação ao curso e ao projeto, pois tinha achado
novos rumos para colocar no projeto mas eu não podia pois ele
já tinha sido definido, e isso me tirou a vontade de terminar o
projeto
4.2 - Prazos
Por todos os desafios e problemas enfrentados,
acabei tendo que definir novos prazos, pois o sistema ainda não
está terminado e pouca implementação foi feita
até agora (eu ditria que só 30% do sistema está
feito). Enfim, os prazos são
- 28/12/2003 - Termino da implementação do sistema
- 31/12/2003 - Versão final com
correções de bugs
O sistema estará disponível em http://www.mac499marzano.cjb.net/
para download, portanto fiquem atentos os interessados
4.3 - Aprendizado
Esse ano, graças ao projeto de formatura tive
um grande aprendizado para a minha vida, pois com todos os problemas
ocorridos acabei tendo que atrasar o lançamento da versão
final do sistema, o que não achei nem um pouco interessante. Eu
aprendi que devo me organizar melhor para que projetos diferentes
não se sobreponham e com isso dificultem o término dos
mesmos. Aprendi também que a pesquiza sobre desenvolvimento de
sistema deve ser feita com muito cuidado, pois você pode cair em
um rumo errado e ter que refazer muitas coisas.
4.4 - Ligação com o BCC
A lista de disciplinas ligadas com o desemvolvimento
foram:
- MAC211 e MAC242 (Laboratório de Programação
1 e 2) - Aprendi a desenvolver projetos longos e consegui minha
primeira experiência real com programação;
- MAC323 (Estrutura de Dados) - Tive que entender bem o conceito de
estruturas de dados para poder escolher qual usar no sistema
- MAC338 (Análise de Algoritmos) - Auxiliou para entender os
algoritmos que executam a análise em Data Mining
- MAC332 (Engenharia de Software) - Tive que usar os conhecimentos
de engenharia de software para projetar sistemas antes de implementar
- MAC426 (Sistemas de Banco de Dados) e MAC439 (Laboratório
de Banco de Dados) - Essas foram as disciplinas mais ligadas
diretamente, pois foi nelas que aprendi a mexer com banco de dados e
adquiri meus primeiros conhecimentos sobre SQL e Data Mining
4.5 - Agradecimentos
- à paciência do Professor João Eduardo
Ferreira, pois ele me aturou esse ano inteiro e algumas vezes me
remotivou a terminar o projeto
- ao professor Carlos Eduardo Ferreira por ter me ajudado muito no
meu curso
- aos professores Paulo Feofiloff e Alan Durham, que me ensinaram a
ter uma disciplina maior em meu curso
- aos meus colegas Alfredo, Carlos, André, Luiz,
César e Jean pela convivência ao longo do curso e pelo
incentivo nas horas mais difíceis
- a minha companheira e amiga Viviane, pois dedicou uma boa parte
do seu tempo para me ajudar e incentivar, coolaborando demais com as
minhas dificuldades
5
- Referências Bibliográficas
Raghu Ramakrishnan e Johannes Gehrke Database
Management Systems McGraw-Hill Science/Engineering/Math, 2002
http://black.rc.unesp.br/IA/cintiab/datamine/teoria.html
Base
teórica do Data Mining
http://www.linux.ime.usp.br/~npaulo/mac439
Nelson Guedes Paulo Junior e Ricardo Hideo Sahara Data Mining: Análise
Determinística
http://www.crie.coppe.ufrj.br/home/capacitacao/teses_mestrado/alexandre-rodrigues.pdf
Alexandre Medeiros Rodriguez Tecnicas
de Data Mining Classificadas do Ponto de Vista do Usuário
http://xin.cz3.nus.edu.sg/group/personal/cx/modules/DM/birch.ppt
Chen Yabing e Cong Gao BIRCH: An
Efficient Data Clustering Method for Very Large Databases
http://www.postgresql.org.br
PostgreSQL-Br
http://geocities.yahoo.com.br/halleypo/pg74/
The PostgreSQL Global Development Group PostgreSQL Documentation