Esse documento contêm informações sobre as atividades realizadas durante o projeto de iniciação científica entitulado "Construção de Agentes Inteligentes para a Web Semântica", módulo integrante do projeto "Busca Inteligente Baseada em Ontologias" (BIBO) que vem sendo financiado pelo CNPq. Esse módulo do projeto BIBO teve inicio em setembro de 2003, tendo como orientadora a professora Dra. Leliane Nunes de Barros.
Essa monografia faz parte das tarefas da disciplina MAC0499 (Trabalho de Formatura Supervisionado). Ela será dividida em duas partes: a primeira contendo a descrição técnica do projeto e a segunda contendo considerações pessoais relacionadas ao curso de Bacharelado em Ciência da Computação e às experiências obtidas durante o projeto.
Gostaria de agradecer todos os integrantes do projeto BIBO em especial à professora Leliane, que me orientou nos últimos 14 meses, fazendo com que hoje eu possa estar escrevendo esta monografia.
Agradeço a todos os professores que contribuiram para minha formação e aos meus colegas que me apoiaram em vários momentos, em especial quando tinha que passar altas horas no laboratório, nos sábados, domingos e feriados para terminar algum trabalho urgente.
Em especial agradeço a Elisa por me inspirar coragem e força para vencer os desáfios do BCC e do projeto de Iniciação Científica, sempre me apoiando em todos os momento.
Um dos principais problemas da Web atual é a recuperação da informação contida nela. Isso acontece porque essa informação não está estruturada nem segue nenhum padrão, sendo a estética a única preocupação, ou seja, que essa informação esteja organizada em páginas feitas para humanos entenderem. Mesmo as melhores ferramentas atuais de busca na Web (como o Google e o Altavista) não são completamente capazes de identificar quais páginas satisfazem a consulta que o usuário faz, trazendo, junto com bons resultados, uma grande quantidade de páginas sem nenhuma ligação com a informação desejada. Outros fatores que dificultam a recuperação de informação é o imenso número de páginas Web e o fato que esse número cresce todos os dias.
Para que a recuperação de informação na Web seja mais precisa e eficiente precisamos fazê-la de forma automática, ou seja, usando computadores. Para isso, é preciso que computadores sejam capazes de compreender o significado das nossas consultas e o significado da informação não estruturada contida na Web. Com esse objetivo foi criada a idéia da Web Semântica, que visa definir o significado da informação através de ontologias - documento que descreve um vocabulário de termos para comunicação entre humanos e sistemas de software. Um dos principais textos sobre o assunto é o artigo "The Semantic Web", publicado em 2001 por Tim Berners-Lee, James Hendler e Ora Lassila na revista Scientific American [15]. Tim Berners-Lee é o inventor da World Wide Web e atualmente um dos diretores da W3C, organização criada para promover o desenvolvimento da Web que lidera uma das principais iniciativas para estudo e desenvolvimento da Web Semântica.
Para o estudo das possibilidades dessa nova área foi criado o projeto "Busca Inteligente Baseada em Ontologias" (BIBO) do grupo LIAMF do Instituto de Matemática e Estatística (IME), que visa identificar os principais problemas da área e as possíveis aplicações.
[topo]Este projeto de Iniciação Científica se concentrou no estudo de desenvolvimento de aplicações para a Web Semântica, comumente chamadas de agentes inteligentes baseados na Web Semântica. Para isso estabelecemos os seguintes objetivos para esse projeto:
Nas próximas seções vamos explorar cada um desses ítens em detalhes.
[topo]"The first step is putting data on the Web in a form that machines can naturally understand, or converting it to that form. This creates what I call a Semantic Web - a web of data that can be processed directly or indirecttly by machines."
-Tim Berners-Lee, Weaving the Web, Harper San Francisco, 1999.
A Web Semântica visa definir o significado da informação contida em documentos Web de forma que um computador, através de agentes de software, seja capaz ter acesso às informações mais relevantes desses documentos. Uma vez tendo acesso a essas informações, queremos que o computador seja capaz de "entender" seu significado para que possa processá-las de maneira automática.
Especificamos a informação relevante de um documento para um agente de software através de marcações semânticas, onde classificamos cada dado relevante do documento dentro de um vocabulário de termos com significado bem definido. Além da classificação, devemos especificar relações entre esses dados.
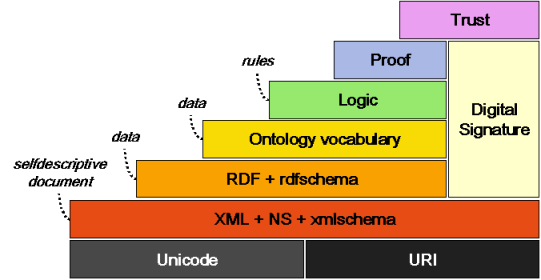
[topo]O modelo abaixo visa padronizar cada nível da construção da Web Semântica. Ele mostra como algumas das tecnologias que estão sendo usadas se encaixam para criar a estrutura necessária para o funcionamento da Web semântica. Seu objetivo é expor que os dados confiáveis na Web Semântica deverão ter consistência lógica e devem ser descritos de tal forma que facilitem o compartilhamento de informação, estrutura e semântica.
Cada nível é construído sobre o nível inferior e cada nível não depende de nenhum de seus níveis superiores. Abaixo vamos definir o papel de cada camada da arquitetura.
Esse nível define quais símbolos podemos usar para descrever metadados e como fazemos referência a um recurso.
Unicode: o conjunto de caracteres aceitos para criar as camadas acima.
URI (Uniform Resource Identifier): maneira de identificar unicamente recursos na Web.
Esses padrões estabelecem a regras iniciais para as linguagens a serem usadas na Web Semântica, utilizando esses padrões, dois agentes serão capazes de trocar dados sem estrutura ou semântica, isso ainda não é suficiente para atingir o total potencial da Web Semântica.
XML(eXtensible Markup Language): linguagem para a representação de dados, é a base de quase todas as linguagens para troca de dados da Web.
NS - Namespace: parecida com nomes de pacotes em
Java, ou seja, é possível indicar onde foi definido um
elemento que queremos usar. Por exemplo:
info:age
info define o endereço onde age foi definida
e age indica qula elemento dentro do endereço queremos
usar.
XMLSchema: permite a criação de vocabulários extremamente simples e a definição de tipos de dados, como inteiro, booleano, etc.
Nesse nível conseguimos definir a estrutura dos metadados, no caso definido pela W3C são triplas (sujeito, predicado, objeto).
RDF(Resource Description Framework): linguagem flexível capaz de descrever qualquer tipo de informação e metadado.
RDFS (RDFSchema): permite a criação de vocabulários básicos em RDF. Aqui já existe a noção de classe, hierarquia e relações (também chamadas de propriedades). RDFS consegue definir propriedades e quais recursos podem fazer parte delas.
Esse nível permite definir um grande número de relações, pois permite que elas sejam mais complexas. Por exemplo, podemos definir uma relação como transitiva ou até como inversa de outra relação. Com ontologias podemos definir classes como união ou intesecção de outras. Hoje, a linguagem adotada para preencher essa camada é a OWL.
Essa camada se confunde um pouco com a camada de lógica e prova, pois uma ontologia só pode ser totalmente compreendida por um agente de software quando houver regras lógicas que o permitam manipulá-la.
Nessa camada podemos definir regras para o tratamento da informação descrita nos níveis inferiores. As regras são responsáveis por parte da "inteligência" do agente de software para a Web Semântica, pois com elas o agente é capaz de inferir nova informação.
Nessa nível podemos verificar a consistência dos dados acessíves na Web Semântica, pois, utilizando a lógica definida no nível inferior, podemos verificar se existem dados contraditórios e apontá-los.
A assinatura digital visa garantir a procedência de um documento ou definição, o que é vital para decidir se uma informação é confiável ou não.
Nessa camada, podemos criar um agente que trabalhem apenas com dados confiáveis na Web Semântica, pois além de poder verificar a consistência dos dados, ele pode ser programado para confiar ou não em uma fonte, pela assinatura digital.
[topo]Baseada na idéia de metadados, a marcação semântica de documentos Web faz com que agentes de software não tenham que processar a informação descrita em linguagem natural (por exemplo, português ou inglês) de páginas Web. O processamento de linguagem natural é difícil por vários motivos, entre eles:
A proposta da Web Semântica para evitar esse problema é de se ter, na construção de páginas Web, um esforço adicional na definição formal do significado da informação que se considera relevante em um documento através de asserções lógicas. Assim, a marcação semântica é feita com base nesta definição fornecendo acesso imediato aos dados relevantes de um documento.
Para a marcação de documentos usamos a linguagem RDF baseada em XML, padrão que vem sendo largamente empregado para troca de informações entre agentes de software. RDF (Resource Description Framework) é a linguagem recomendada pela W3C para descrição de metadados, desenvolvida especificamente para a marcação de documentos.
Para a especificação formal do vocabulário usado para a marcação de um documento usamos ontologias, que possibilitam a troca de informação semântica entre humanos e agentes de software, isso permite que um computador "entenda" um certo domínio de aplicação especificado.
Exemplo de marcação semântica de uma página pessoal (homePage.html). Aqui temos descritos:
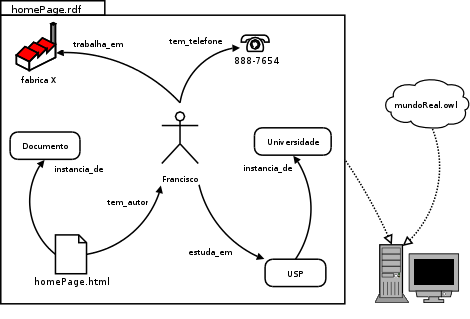 |
Quando uma agente de software acessa os metadados (descritos em homePage.rdf) e a ontologia (mundoReal.owl) que define o vocabulário usado, ele é capaz de consultar a informação, cruzar dados com outras páginas marcadas que usam a mesma ontologia e verificar possíveis inconsistências. |
A linguagem RDF foi criada para fazer pela informação processável por computadores o mesmo que a World Wide Web fez pelo hypertexto: permitir que os dados sejam processados fora de um ambiente particular onde ele foi criado, de maneira que eles sejam manipulados na escala da Internet. Para isso ela tem os seguintes objetivos:
Para atender seus objetivos, RDF foi desenvolvida com as seguintes características:
Um documento RDF é um conjunto de triplas do tipo: (sujeito, predicado, objeto), onde predicado é uma recurso especial chamado de propriedade, que relaciona os os dois outros recursos da tripla. Um documento RDF pode ser representado por um grafo, onde os recursos(nós) estão relacionados através das propriedades(arcos), como na figura acima. Para identificar unicamente cada recurso no RDF usamos URIs(Uniform Resource Identifier), que podem ser entendidos como o endereço (na Web) onde o recurso foi definido.
Quando usamos RDF não podemos assumir que existe informação completa sobre qualquer recurso. RDF não previne a criação de informação errada ou inconsistente. Os desenvolvedores de aplicativos que usam RDF devem estar cientes disto e preparar suas aplicações para tolerar fontes informação incompletas e possívelmente contraditórias.
[topo]Uma ontologia define termos para que um agente de software consiga extrair o máximo de informação possível de um documento. A linguagem que vem sendo desenvolvida para a descrição de ontologias é a OWL (Web Ontology Language) [10] , que é baseada na linguagem RDF e em lógica de descrição.
As ontologias permitem que possamos descrever formalmente um certo domínio de aplicação sob um ponto de vista específico pois, normalmente, não estamos interessados em todos os pontos de vista possíveis (no exemplo acima não estamos interessados nos impactos socias da fábrica X, apenas queremos descrevê-la como local de trabalho).
Uma ontologia pode facilmente ser estendida e assim, reaproveitamos definições já construídas e mantemos uma linguagem comum entre todas as ontologias que estendem uma ontologia, por exemplo, a ontologia mundoReal.owl descrita a seguir.
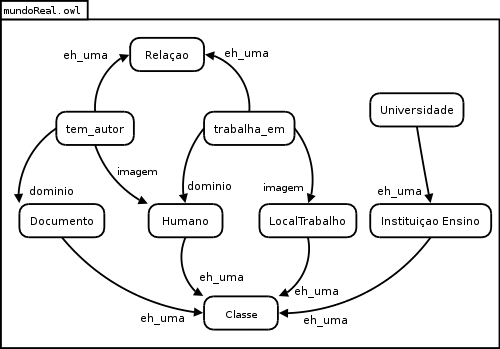
Abaixo temos o esquema gráfico de uma parte da ontologia mundoReal.owl:
|
Aqui vemos as classes:
Uma relação deve ter domínio e imagem para indicar quais classes ela envolve. No uso da relação trabalha_em (Francisco, trabalha_em, fábricaX), temos Francisco como sujeito, trabalha_em como predicado e fábricaX como objeto. Pela definição da relação trabalha_em podemos inferir que Francisco é da classe Humano e que fábricaX é da classe LocalTrabalho. |
O dicionário Houaiss define inferência
como:
"operação intelectual por meio da qual se afirma a
verdade de uma proposição em decorrência de sua
ligação com outras já reconhecidas como
verdadeiras"
Por meio da inferência, um agente é capaz de tornar explícita uma informação que ainda não estava escrita claramente, mas que pode ser derivada a partir de outras já conhecidas. A figura abaixo mostra alguns exemplos de informações que podem ser inferidas a partir da página pessoal do Franciso e da ontologia MundoReal.owl.
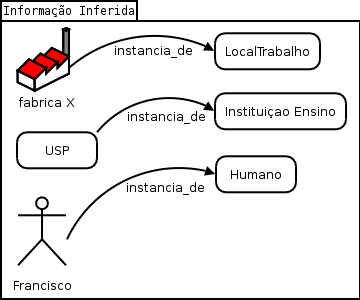
Agentes de software desempenham um papel importantíssimo para a viabilização da Web Semântica pois, uma vez que os metadados estão disponíveis na Web, precisamos de mecanismos para processá-los e aplicações úteis para utilizá-los.
Dentro da área de Inteligência Artificial, define-se agente de software da seguinte maneira: entidade capaz de perceber o ambiente onde está, processar essa informação e atuar sobre esse ambiente de maneira a atingir algum objetivo.
O ambiente considerado no contexto da Web Semântica é a própria Web Semântica ou uma parte dela. Esse ambiente é dinâmico, pois a qualquer momento ele pode ser alterado sem que nosso agente possa prever. Um agente realiza uma percepção desse ambiente quando lê a marcação de um documento. Um agente pode atuar no ambiente quando ele modifica o conjunto dos documentos presentes na Web Semântica, um exemplo de atuação é remover alguma inconsistência dentro de um documento. O processamento que um agente pode fazer (usando o exemplo anterior) é, depois de ler alguns documentos, verificar quais deles apresentam inconsistência.
[topo]Para estudar e avaliar novas tecnologias que estão sendo desenvolvidas na Web Semântica foi criado o projeto Busca Inteligente Baseada em Ontologias (BIBO). Este projeto foi subdividido em três módulos: Currículo Lattes e Web Semântica - preocupado com a construção de uma ontologia para a plataforma Lattes do CNPq; Minimização da padronização de páginas HTML para compartilhamento de informações - se concentrou na extração automática de dados de documentos HTML em linguagem natural e Construção de Agentes Inteligentes para a Web Semântica aqui apresentado.
No módulo Construção de Agentes Inteligentes para a Web Semântica visamos ter contato com as tecnologias existentes para a criação de aplicações baseadas em Web Semântica. Como o princípio da Web Semântica é a existência de páginas da WWW contendo marcações semânticas baseadas em ontologias, nossa proposta é a de investigar a capacidade de fazer consultas nessa nova tecnologia, isto é, consultas a páginas com marcações semânticas.
Em resumo, os objetivos desse projeto abrangem duas questões principais:
O estudo de marcações semânticas de documentos e processamento dos metadados nos levou a um estudo de caso envolvendo vários aspectos da Web Semântica, desde representação de conhecimento até a implementação de um agente capaz de tratar a informação em um domínio específico.
Para estudar a recuperação de informação disponível na Web analisamos algumas ferramentas de busca. Isso nos levou a estudar o funcionamento da Google Web APIs [03].Para a construção de um agente baseado na Web Semântica, capaz de recuperar informação disponível na Web, seria ideal que ele fosse capaz de fazer buscas em larga escala de páginas marcadas semanticamente (com metadados). Porém, para realizar esse tipo de busca é necessário um grande sistema de software e uma grande infra-estruta de hardware. Como já existem ferramentas que fazem busca em larga escala pela Web, estudamos como automatizar o uso destas ferramentas para buscar metadados. Uma maneira viável de automação é o uso de Serviços Web (Web Services) para utilização da ferramenta de busca via software. Neste projeto, utilizamos a Google Web APIs, um Serviço Web que fornece acesso a todos os serviços de busca que, de outra maneira, só poderiam ser acessados com supervisão humana ou criando um programa para analisar o código HTML gerado como resultado da consulta do Google [02].
Para estudar as funcionalidades desse Serviço Web criamos um programa em Java capaz de se comunicar com o mesmo. Esse programa apresenta uma interface gráfica para o usuário que facilita a criação das consultas e a visualização do resultado. Com ele verificamos que o Google consulta apenas o conteúdo acessível a humanos, ou seja, aquele que o navegador exibe após analisar o código HTML de uma página e não se preocupa com os metadados. Na verdade, ele verifica alguns tags HTML (como o tag para título e para apontadores), mas para o nosso projeto precisaríamos consultar o conteúdo de todos os tags com metadados sobre um documento.
Como resultado dessa investigação concluímos que através da Google Web APIs versão beta2 não é possível recuperar exclusivamente páginas com marcação semântica. Com isso, decidimos partir para um estudo de caso, sem utilizar ferramentas de busca, ou seja,partindo do princípio que é possível localizar páginas com marcação semântica, por exemplo, como serviços de Páginas Amarelas com publicação de Serviços Web. A partir disso, nosso enfoque para esse projeto é o de processamento da informação com marcação semântica e construção de agentes inteligentes para a Web Semântica.
[topo]Para verificar a capacidade da Web Semântica e ter contato com a tecnologia existente decidimos criar um agente capaz de responder algumas perguntas dentro do domínio acadêmico, mais especificamente, na recuperação de informações das páginas do Departamento de Ciência da Computação do IME (DCC-IME). Inicialmente, nosso estudo de caso envolveu a seleção de algumas das perguntas que gostaríamos que nosso agente fosse capaz de responder:
Essas perguntas foram elaboradas acreditando-se que, para respondê-las, é preciso associar diferentes páginas do DCC-IME, construídas por diferentes autores empregando diferentes termos para conceitos similares. Assim, um agente inteligente capaz de responder corretamente a essas perguntas deve ser capaz de consultar uma ontologia que correlacione os termos encontrados nessas páginas.
É importante notar que, de acordo com a proposta da Web Semântica, páginas Web deverão ser criadas com base em uma ou mais ontologias. Para esse projeto, uma vez que as páginas do DCC não foram originalmente criadas com base em ontologias, foi necessário criar as marcações de maneira artifical, ou seja, olhamos o conteúdo em linguagem natural de algumas páginas e geramos a marcação semântica segundo os termos de uma ontologia escolhida.
Assim, a construção do agente inteligente para Web Semântica envolveu: (i) a representação da informação na Web Semântica e (ii) a implementação do agente propriamente dito.
Como dissemos anteriormente, a representação de informação na Web Semântica é feita através de marcação de páginas acessíveis pela Web. Para o nosso estudo de caso resolvemos utilizar as páginas de alguns docentes do DCC-IME. Para isso, precisamos adotar uma ontologia que descreve o domínio e de instanciações dessa ontologia para cada página.
Abaixo temos um exemplo de marcação semâmtica de página de professor, no caso, da professora Leliane.
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE owl [
<!ENTITY owl "http://www.w3.org/2002/07/owl#">
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#">
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
<!ENTITY dc "http://purl.org/dc/elements/1.1/">
<!ENTITY dct "http://purl.org/dc/terms/">
<!ENTITY support "http://www.aktors.org/ontology/support#">
<!ENTITY portal "http://www.aktors.org/ontology/portal#">
<!ENTITY base "http://www.linux.ime.usp.br/~ghsilva/websemantica/leliane.owl">
<!ENTITY leliane "http://www.linux.ime.usp.br/~ghsilva/websemantica/leliane.owl#">
<!ENTITY ime "http://www.linux.ime.usp.br/~ghsilva/websemantica/ime.owl#">
]>
<rdf:RDF
xmlns = "&base;"
xmlns:owl = "&owl;"
xmlns:rdf = "&rdf;"
xmlns:rdfs = "&rdfs;"
xmlns:dc = "&dc;"
xmlns:dct = "&dct;"
xmlns:xsd = "&xsd;"
xmlns:support = "&support;"
xmlns:portal = "&portal;"
xmlns:ime = "&ime;"
xmlns:leliane = "&leliane;"
xml:base = "&base;">
<owl:Ontology rdf:about="&base;">
<rdfs:label xml:lang="pt-br"></rdfs:label>
<dc:title xml:lang="pt-br"></dc:title>
<dc:description xml:lang="pt-br">
Marcação da página da professora Leliane
</dc:description>
<dc:creator>projeto BIBO</dc:creator>
<dc:creator>George Henrique Silva</dc:creator>
<dct:created rdf:datatype="&xsd;date">2004-02-05</dct:created>
<dc:source rdf:resource="http://www.ime.usp.br/~leliane"/>
<owl:versionInfo>1.0</owl:versionInfo>
<owl:imports rdf:resource="http://www.aktors.org/ontology/portal"/>
<owl:imports rdf:resource="http://www.linux.ime.usp.br/~ghsilva/websemantica/ime.owl"/>
</owl:Ontology>
<portal:Professor-In-Academia rdf:ID="Leliane">
<portal:works-for rdf:resource="&ime;USP"/>
<portal:works-in-unit rdf:resource="&ime;DCC"/>
<portal:has-academic-degree rdf:resource="&portal;PhD"/>
<rdfs:isDefinedBy rdf:resource="&base;"/>
</portal:Professor-In-Academia>
</rdf:RDF>
O ponto de partida foi a linguagem Simple HTML Ontology Extensions (SHOE) [08], uma das primeiras linguagens para marcação semântica de documentos HTML. Ela define novos tags capazes de disponibilizar metadados no meio do código HTML. Mas o projeto desta linguagem foi descontinuado.
Um dos criadores da linguagem SHOE, James A. Hendler, passou a fazer parte da equipe de desenvolvimento da linguagem OWL - Web Ontology Language. O objetivo dessa linguagem é se tornar um padrão para o desenvolvimento de ontologias, na época ela estava sendo especificada mas já existiam alguns trabalhos em Web Semântica usando essa linguagem.
Decidimos então usar a linguagem OWL para a representação de informação no nosso projeto. Para cada página a ser marcada criamos um arquivo com os metadados da página em questão, essa decisão de manter os metadados separados do arquivo HTML foi feita para facilitar o processo de leitura dos metadados e porque ainda não existe uma posição oficial de como inserir marcações OWL em páginas HTML. Isso porque ao inserir OWL em HTML a página pode se tornar inválida, esse problema só será resolvido com uma nova especificação da linguagem HTML.
Após um estudo da capacidade e expressividade da linguagem, começamos a trabalhar no desenvolvimento da ontologia para descrever o domínio DCC-IME. Para visualizar e editar ontologias utilizamos o editor Protégé [05], que suporta OWL e apresenta uma interface amigável.
Para a contrução de um agente para Web Semântica escolhemos usar o arcabouço Jena na versão 2.1, pois ele fornece toda a base necessária para acessar e processar a informação descrita especialmente para a Web Semântica. Como o Jena foi desenvolvido na linguagem Java, foi fácil escolher a linguagem para desenvolvimento do agente.
Inicialmente fizemos um estudo (resumido na seção Jena) da capacidade do Jena para trabalhar com RDF e fazer consultas usando a linguagem RDQL [07] - que trata um documento RDF como um conjunto de triplas sem qualquer estrutura ou semântica. Uma vez que a linguagem OWL é construída tendo como base o RDF, numa primeira etapa do nosso estudo de caso, foi feita uma simplificação do uso de OWL considerando apenas a estrutura de triplas do RDF. Os testes nesta fase consistiram na implementação de uma interface gráfica para carregar um arquivo RDF localmente e gerar consultas RDQL, formatando o resultado em uma tabela.
Recentemente, estendemos a implementação para aproveitar algumas características da linguagem OWL (como a importação de outros documentos e o uso do mecanismo de inferência) para aproveitar melhor as características de um documento nessa linguagem. Essa implementação de interface de consultas servirá como base para criar um agente especializado em responder perguntas em qualquer domínio, no nosso caso o domínio DCC- IME.
A interface de consultas permite que o usuário passe uma lista de arquivos (OWL ou RDF) contendo marcações semânticas para serem consultadas. Esses arquivos podem ser visualizados para facilitar a verificação de seus dados originais. Permitimos a configuração de quais características de OWL o usuário quer explorar, como permitir a importação de outros documento, ou decidir usar motor de inferência ou não.
Uma vez que os arquivos foram carregados e configurados, o usário pode realizar três classes de consultas:
Devido à grande complexidade de escrever uma ontologia que descreva o meio acadêmico de Ciência da Computação, procuramos alguma ontologia já existente que suprisse nossas necessidades. Encontramos no site da linguagem DAML(DARPA Agent Markup Language) [01] uma biblioteca de ontologias, algumas delas em OWL. A ontologia Portal Ontology [06] - criada para descrever uma comunidade acadêmica de Ciência da Computação - contém a modelagem de grande parte do domínio acadêmico de Ciência da Computação e portanto decidimos adotá-la como base. Para os elementos que não estavam definidos, criamos uma extensão da ontologia base, por exemplo, a definição do conceito de Departamento.
Abaixo está o arquivo que define os conceitos que precisávamos criar para o nosso projeto:
[topo]
<?xml version='1.0' encoding='ISO-8859-1'?>
<!DOCTYPE owl [
<!ENTITY owl "http://www.w3.org/2002/07/owl#">
<!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#">
<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">
<!ENTITY dc "http://purl.org/dc/elements/1.1/">
<!ENTITY dct "http://purl.org/dc/terms/">
<!ENTITY baseportal "http://www.aktors.org/ontology/portal">
<!ENTITY portal "http://www.aktors.org/ontology/portal#">
<!ENTITY base "http://www.linux.ime.usp.br/~ghsilva/websemantica/departament.owl">
<!ENTITY departament "http://www.linux.ime.usp.br/~ghsilva/websemantica/departament.owl#">
]>
<rdf:RDF
xmlns:owl = "&owl;"
xmlns:rdf = "&rdf;"
xmlns:rdfs = "&rdfs;"
xmlns:dc = "&dc;"
xmlns:dct = "&dct;"
xmlns:xsd = "&xsd;"
xmlns:portal = "&portal;"
xmlns:departament = "&departament;"
xml:base = "&base;">
<owl:Ontology rdf:about="&base;">
<rdfs:label xml:lang="pt-br">Definição de um departamento de uma faculdade</rdfs:label>
<dc:title xml:lang="pt-br">Departamento</dc:title>
<dc:title xml:lang="en">Departament</dc:title>
<dc:description xml:lang="pt-br">
Define o conceito de departamento e algumas relações
</dc:description>
<dc:creator>projeto BIBO</dc:creator>
<dc:creator>George Henrique Silva</dc:creator>
<dct:created rdf:datatype="&xsd;date">2004-05-13</dct:created>
<dc:source rdf:resource="&portal;"/>
<owl:versionInfo>1.0</owl:versionInfo>
<owl:imports rdf:resource="&baseportal;"/>
</owl:Ontology>
<!-- Definicao de departamento -->
<owl:Class rdf:ID="Departament">
<rdfs:subClassOf rdf:resource="&portal;Educational-Organization-Unit"/>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="&portal;unit-of-organization"/>
<owl:allValuesFrom rdf:resource="&portal;University-Faculty"/>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:isDefinedBy rdf:resource="&base;"/>
</owl:Class>
<owl:ObjectProperty rdf:ID="has-departament">
<rdfs:domain rdf:resource="&portal;University-Faculty"/>
<rdfs:range rdf:resource="&departament;Departament"/>
<rdfs:isDefinedBy rdf:resource="&base;"/>
</owl:ObjectProperty>
</rdf:RDF>
Jena é um arcabouço para construção de aplicações voltadas à Web Semântica, foi desenvolvido pelo HP LABS [04] e fornece um ambiente de programação para as linguagens RDF, RDFS, OWL e DAML+OIL, inclui motor de inferência, possibilitando ainda a persistência em banco de dados.
Nas próximas subseções vamos descrever os principais módulos que compõem o Jena e suas características.
A API para RDF é o módulo central do Jena, todos os outros módulos ou são baseados nele ou trabalham diretamente com ele. Esse módulo é o responsável por criar uma representação interna de um documento RDF (através de um grafo) e fornecer métodos de acesso e manipulação desse documento. Cada tripla RDF (sujeito, predicado, objeto) é representada no grafo como um arco, pois um arco é definido por sua origem (sujeito), seu destino (objeto) e um nome associado ao arco (propriedade), como na figura XXXXXX.
Vamos listar, as principais funcionalidades dessa API:
RDQL é a linguagem de consultas para RDF usada pelo Jena. Ela usa um modelo de consultas orientado a dados que complementa as consultas permitidas pela API para RDF.
Essa linguagem é dita orientada a dados, pois não envolve inferência nem semântica, apenas analisa o documento como um conjunto de triplas, sem se preocupar com qualquer informação descrita nas ontologias usadas.
A sintaxe da RDQL é parecida com a do SQL:
SELECT ?resource
WHERE (?resource info:age ?age)
AND ?age >= 24
USING info FOR
No exemplo acima, a consulta pede "todo recurso que tem a propriedade identificada pelo URI http://somewhere/peopleInfo#age e que o valor dela seja maior ou igual a 24".
O módulo de suporte a ontologias do Jena utiliza a API para RDF como base e permite o uso das linguagens RDFS, DAML+OIL, OWL LITE, OWL DL e OWL FULL. Como o Jena é bem modularizado, ele permite que qualquer linguagem de descrição de ontologias seja aceita, desde que o programador interessado implemente as classes necessárias.
Essa API permite que as características e poder de descrição de uma ontologia sejam totalmente utilzadas por um agente de software interessado. Ela cria algumas camadas de "inteligência" sobre as informações contidas em um documento. Essas camadas estão representadas na seguinte figura:
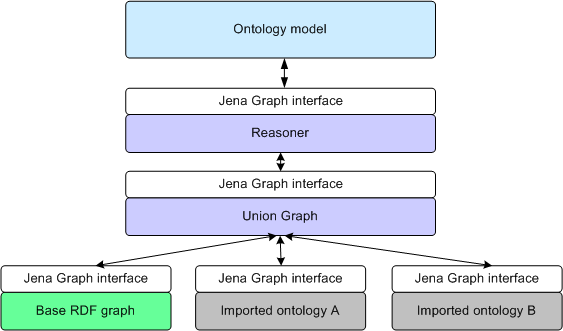
Na camada mais baixa temos, dentro do retangulo verde, o documento que estamos trabalhando e, nos demais retangulos cinza do mesmo nível, as ontologias que estão sendo usadas por ele. No nível acima (Union Graph) temos a união de todos os documentos do nível inferior, para que possamos usar toda a informação descrita nas ontologias, juntamente com o arquivo que queremos trabalhar. Para extrair toda a informação implicita nesse documentos utilizamos a próxima camada (Reasoner), que se baseia em regras lógicas para extrair a informação desejada. Por fim, na camada mais alta (Ontology Model), é que teremos acesso para fazer consultas no nosso documento. Com esse modelo, as consultas que realizamos podem se ditas "inteligentes", pois devolvem muito mais informação do que esperaríamos apenas olhando para o documento inicial.
Usados pela API para Ontologias, os motores de inferência fornecem acesso as informações implicitas nas ontologias. Eles estão diretamente ligados às camadas de lógica e prova da arquitetura da Web Semântica. O Jena fornece alguns motores de inferência pré-construídos e ainda a possibilidade de criarmos novos motores quando necessário, ou mesmo estender os já existentes.
Os motores de inferência pré-contruídos fazem um grande papel no suporte das lingugens aceitas pelo Jena (RDFS, DAML+OIL e OWL). Mas eles ainda não estão em sua versão final, pois alguns tem problemas de eficiência (são muito lentos ou pesados) e outros não atendem à todas as regras definidas para uma linguagem (como o motor de inferência para OWL). A documentação completa sobre os motores de inferência e tudo mais sobre o Jena está em [04].
[topo]Um dos resultados mais relevantes do nosso trabalho em Web Semântica, além do aprendizado sobre os diferentes aspectos dessa nova tecnologia, foi a identificação e implementação de diferentes tipos de consultas que podem ser realizadas na Web Semântica. Essas diferentes consultas caracterizam diferentes tipos de agentes para a Web Semântica, cada um com uma capacidade de raciocínio mais complexa que o outro. Dessa forma, a definição de agente inteligente para a Web Semântica pode ser feita de forma incremental.
Para cada uma das classes de consultas que o agente construído nesse projeto pode realizar, podemos utlizar um nível diferente de complexidade, de acordo com o tipo de aplicação que desejamos, ou o tipo de agente que precisamos.
São consultas que podem ser realizadas sem o uso das ontologias que definem os termos usados nas páginas consultadas.
Esse é o tipo de consulta mais
simples, pois leva em consideração apenas a
marcação sintática de um documento e não
realiza nenhum tipo de processamento da informação a ser
consultada, apenas filtra o que interessa. Sendo assim, ela é
mais apropriada para ser usada em documentos estruturados em puro RDF.
É importante notar que, apesar desse tipo de consulta não recuperar ou processar ontologias, marcações semânticas diferenciam termos iguais, ou seja, o termo "autor" pode ocorrer no mesmo do documento porém com significados diferentes.
Esse exemplo se aplica no caso onde temos, uma ontologia que modela filmes e outra que modela artigos científicos, em ambas o termo "autor" é definido, mas cada um apresenta um significado para o contexto em que ele foi definido. Como os dois tipos de autores têm diferentes URIs, o agente de software consegue diferenciá-los.
São consultas baseadas na semântica da linguagem adotada para descrever ontologias e na definição do vocabulário usado para marcação das páginas consultadas.
Esse tipo de consulta aproveita a semântica contida nas ontologias usadas na marcação de uma página para gerar consultas mais completas pois, utilizando um motor de inferência, temos acesso à informação implícita em um documento.
A abordagem que vamos usar (é a abordagem escolhida pela equipe que desenvolveu o Jena) é a de separar o processo de inferência do processo de consulta em si. Primeiro, utilizamos um motor de inferência baseado em regras (que contêm boa parte das regras semânticas da linguagem OWL) para gerar TRIPLAS que serão relevantes (OU NÃO) para a consulta desejada e depois fazemos uma consulta direta sobre os dados originais junto com os dados inferidos, gerando uma consulta "inteligente".
O processo de infer�ncia pode ocorrer de duas maneiras: usando encadeamento para frente(forward chaining) ou encadeamento para tr�s (backward chaining).
Utilizando um motor de infer�ncia no modo forward chaining, onde todos os dados relevantes da p�gina s�o enviados ao motor de infer�ncia. Toda regra disparada que criar uma tripla, ir� inser�-la no grafo interno de dedu��es e essa nova tripla pode ser usada para disparar outras regras. Triplas removidas podem fazer com que regras sejam disparadas tamb�m.
O motor de infer�ncia com forward chaining utiliza o algoritmo RETE, portanto ele age incrementalmente quando novas triplas s�o inseridas [17]. Neste modo, o motor de infer�ncia gera mais triplas que o necess�rio para uma consulta espec�fica, mas por outro lado, todo o processamento � feita uma �nica vez, fazendo com que as pr�ximas consultas sejam executadas maisrapidamente.
Utilizando um motor de infer�ncia no modo backward chaining, ser� usada uma estrat�gia semelhante � do Prolog. Quando uma p�gina � consultada, a consulta � traduzida para uma meta e o motor de infer�ncia aplica as regras de modo a tentar atingir essa meta, casando as triplas armazenadas com as regras de backward chaining. Neste caso, o motor de infer�ncia n�o trabalha incrementalmente, isto �, sempre que os dados originais forem alterador, todo o processamento realizado � jogado fora. Neste modo, geralmente, um conjunto bem menor de triplas � gerado (dependendo da consulta, dos dados originais e das regras), fazendo com que o processo de infer�ncia seja mais r�pido e mais espec�fico para a consulta desejada.
São consultas com inferência que utilizam, além da informação semântica das ontologias usadas e das informações contidas nas páginas consultadas, o conhecimento específico do agente sobre o domínio.
Além de herdar as características das consultas com inferência, esse tipo de consulta possibilita o uso de conhecimento sobre o domínio que não pode ser representado por ontologias, ou que não fazem parte do escopo tratado pela ontologia escolhida.
Um exemplo deste tipo de conhecimento é o de preferências do usuário que podem ser aprendidas por um agente que utilize esse conhecimento em suas próximas consultas.
Exemplo: Tenho um agente que procura pizzarias quando digito um sabor de pizza que eu quero comer. Nas minhas configurações do agente, disse que não gosto de pizzas com cebola, assim o agente elimina do resultado as pizzarias que colocam cebola naquele sabor de pizza que eu escolhi.
Utilizando a ontologia escolhida no nosso estudo de caso podemos responder as perguntas listadas inicialmente utilizando as seguintes consultas RDQL:
Nesse caso estamos todos os professores (1) que trabalham no DCC (2).SELECT ?x 1 WHERE (?x, rdf:type, portal:Professor-In-Academia), 2 (?x, portal:works-in-unit, <http://www.linux.ime.usp.br/~ghsilva/websemantica/ime.owl#DCC>) USING rdf FOR <http://www.w3.org/1999/02/22-rdf-syntax-ns#>, portal FOR <http://www.aktors.org/ontology/portal#>
Nesse caso estamos verifcar se X é um professore (1) e listar quais projetos ele coordena(2). Onde X é a URI do professor que estamos consultandoSELECT ?projeto 1 WHERE (X, rdf:type, portal:Professor-In-Academia), 2 (?projeto, portal:has-project-leader, X) USING rdf FOR <http://www.w3.org/1999/02/22-rdf-syntax-ns#>, portal FOR <http://www.aktors.org/ontology/portal#>
As demais consultas podem ser facilmente criadas em RQDL e com a definição da ontologia que adotamos.
[topo]Entrei nesse projeto de Iniciação Científica para ter uma experiência com um trabalho de pesquisa acadêmica, e conhecer melhor a área de Inteligência Artificial, uma vez que so tinha cursado a matéria MAC0239-Métodos Formais em Programação, que é o primeiro contato dos alunos do BCC com uma disciplina de lógica e gostei bastante.
Outro fator que me atraiu, foi o tema do projeto, pois ele involvia a WWW, área que conhecia muito pouco, além do que um usuário comum conhece.
[topo]
Um dos maiores desafios desse projeto foi lidar com uma área de pesquisa tão nova que não contém livros didáticos nem mesmo padrões totalmente estabelecidos. Isso exigiu uma grande interação com minha orientadora durante o começo do projeto para que eu não me "perdesse" durante as pesquisas. Isso me lembra uma pequena frustração: poucas semanas antes do fim do projeto foram comprados livros recém-publicados que cobrem todos os principais conceitos que estudamos durante o início do projeto, de tal maneira que se eles existissem há um ano atrás teríamos evitado alguns meses de buscas por informação na Web. Sendo assim, um dos principais desafios foi a pesquisa e aprendizagem de uma grande quantidade de novos conceitos, não vistos antes em nenhuma disciplina do BCC, entre eles:
Uma coisa surpreendente na Web
Semântica é que, apesar das dificuldades iniciais
descritas a cima, hoje, cerca de 5 anos depois dos trabalhos iniciais,
já existe uma grande convergência das tecnologias
desenvolvidas, pois um grande número de pesquisas e
aplicações envolvem as tecnologias propostas como
padrão, gerando uma concentração de
esforços na mesma direção.
Um dos desáfios que eu não esperava enfrentar foi a criação de interfaces gráficas em Java. Tive que passar muitas horas estudando a API de Java 1.4.2 e os tutorias sobre Swing para criar componentes que eu imaginava simples. Inicialmente não considerei a necessidade de usar alguma ferramenta para criação de interfaces gráficas, mas hoje vejo que seria de grande auxílio.
Trabalhar com o Jena foi um ponto
muito importante da minha Iniciação Científica,
pois pela primeira vez trabalhei com um arcabouço, inclusive eu
nem entendia o que significava arcabouço até cursar a
disciplina MAC0413 - Tópicos de Programação
Orientada. O Jena é formado por diversos módulos e para
extrair o máximo dele tive que me dedicar ao estudo de
praticamente toda a sua documentação, o que levou mais
tempo do eu queria, mas valeu a pena pelo resultado que obtive na
implementação da interface de consultas.
Acredito que quase todos os tópicos estudados para esse projeto se aplicam para situações reais, pois como tivemos uma abordagem pragmática para tratar a Web Semântica durante as pesquisas, tudo que estudei pode ser aplicado direta ou indiretamente na construção de ferramentas que trabalhem com representação de conhecimento, que é o caso da Web Semântica.
A experiência proporcionada pelo curso de BCC foi muito importante em vários aspectos do meu projeto, desde a especificação de algumas tarefas, passando pela apresentação de seminários, até a implimentação de software. E essa experiência será totalmente aplicada em situações reais, fora do ambiente acadêmico "controlado".
[topo]Nosso grupo de trabalho interagiu através de lista de email e de reuniões. Mas acredito que essa interação deveria ter sido mais forte. Não estou falando da interação com minha orientadora, pois tinhamos reuniões semanais, mas da troca de informação entre todos os componentes do projeto BIBO.
Essa pequena interação se deu pelo problema de conflito de horários, pois sempre que queríamos marcar uma reunião, passávamos quase duas semana para consegui-lo. Sem falar em semana de provas e EPs, principalmente nos fins de semestre, quando nem orientadores nem orientados conseguiam sequer trocar emails.
Gostaria de ter tido mais tempo disponível para trabalhar no meu projeto de iniciação, mas acredito que o tempo que consegui foi muito bem aproveitado, pois adquiri um ótimo conhecimento teórico sobre Web Semântica e ainda consegui gerar um aplicativo funcional para verificar o que realmente já poderia ser colocado em prática.
[topo]unicode: representação de caracteres em 16 bits que associa códigos únicos de caracteres para cada caracteresde várias línguas existentes. Diferente do ASCII, representação de caracteres que define 128 caracteres distintos em 8 bits, o Unicode é capaz de representar 65.536 caracteres distintos.
Departamento de Ciência da Computação - Instituto de Matemática e Estatística - Universidade de São Paulo